In the realm of modern data management, the choice between relational and non-relational databases has a profound impact on how businesses handle their data. These two database models offer distinct approaches to storing, retrieving, and managing data. Each has its own set of strengths and weaknesses that cater to different use cases and scenarios. In this blog post, we’ll delve into the key differences between relational vs nonrelational databases to help you make informed decisions for your data storage needs.
What is a Database?
A database is a structured collection of data that is organized, stored, and managed in a way that allows for efficient retrieval, manipulation, and analysis of information. It serves as a centralized repository for storing and organizing a wide range of data, such as text, numbers, images, videos, and more. Databases are commonly used in various applications and industries to manage large amounts of information and provide reliable and secure access to that data.
Key characteristics of a database include:
-
Structure:
Databases have a defined structure that specifies how data is organized and how different pieces of information relate to each other. This structure is typically defined using a schema, which outlines the tables, columns, data types, relationships, and constraints that the database will use.
-
Data Management:
Databases enable efficient data management by allowing users to insert, update, delete, and retrieve data. This is typically done using a query language, such as SQL (Structured Query Language), which provides a standardized way to interact with the database.
-
Data Integrity:
Databases ensure data integrity by enforcing rules and constraints on the data. These constraints can prevent the insertion of invalid data, maintain consistency, and ensure accuracy in the stored information.
-
Concurrency Control:
Databases often support multiple users accessing and modifying data simultaneously. Concurrency control mechanisms ensure that data remains consistent and that transactions do not interfere with each other.
-
Security:
Databases offer security features to control access to the data. This includes user authentication, authorization, and encryption to protect sensitive information from unauthorized access.
-
Scalability:
Databases can be designed to handle various levels of data volume and user loads. They can be scaled vertically (adding more resources to a single machine) or horizontally (distributing data across multiple machines).
-
Indexing:
Indexes are used to optimize data retrieval by creating efficient pathways to the data. They speed up query performance by allowing the database to quickly locate relevant records.
-
Backup and Recovery:
Databases provide mechanisms for creating backups of data and facilitating recovery in case of data loss or system failures.
There are different types of databases, including relational databases (like MySQL, PostgreSQL, and Oracle), NoSQL databases (like MongoDB and Cassandra), and specialized databases for specific purposes (like time-series databases or graph databases). Each type serves specific use cases and has its own advantages and limitations.
Understanding Relational Databases
Relational databases have been the stalwarts of data storage for decades. They follow the relational model and organize data into structured tables with predefined schemas. Each row in a table represents a record, while columns represent attributes or fields. The relationships between tables are established through keys, usually primary and foreign keys, which maintain data integrity and ensure consistency.
Key Characteristics of Relational Databases:
-
Structured Data:
Data is stored in well-defined tables with fixed schemas, making it suitable for structured data.
-
ACID Transactions:
Relational databases offer strong transactional support, ensuring data consistency and integrity even in the face of failures.
-
Data Integrity:
Referential integrity is enforced through constraints, preventing orphaned or inconsistent data.
-
Complex Queries:
SQL (Structured Query Language) is used to perform complex queries that involve multiple tables and conditions.
-
Scalability Challenges:
Traditional relational databases may face scalability challenges when handling massive amounts of data and high-velocity workloads.
Understanding Non-Relational Databases
Non-relational databases, often referred to as NoSQL databases, have gained prominence with the rise of modern web applications and big data. Unlike relational databases, they do not adhere to a fixed schema and offer more flexible data models. NoSQL databases prioritize scalability and performance, making them suitable for applications that require handling vast amounts of unstructured or semi-structured data.
Key Characteristics of Non-Relational Databases:
-
Schema Flexibility:
NoSQL databases allow for dynamic and evolving data structures, enabling agile development and accommodating various data formats.
-
Horizontal Scalability:
They are designed for seamless distribution across multiple servers or nodes, making them highly scalable for massive workloads.
-
Variety of Data Models:
NoSQL databases include document stores, key-value stores, column-family stores, and graph databases, catering to different data storage requirements.
-
Eventual Consistency:
Many NoSQL databases prioritize availability and partition tolerance over immediate consistency, offering eventual consistency models.
-
Simplified Queries:
NoSQL databases may use different query languages, APIs, or even object-based access for simplified and efficient data retrieval.
How does Relational vs Non-Relational Database work?
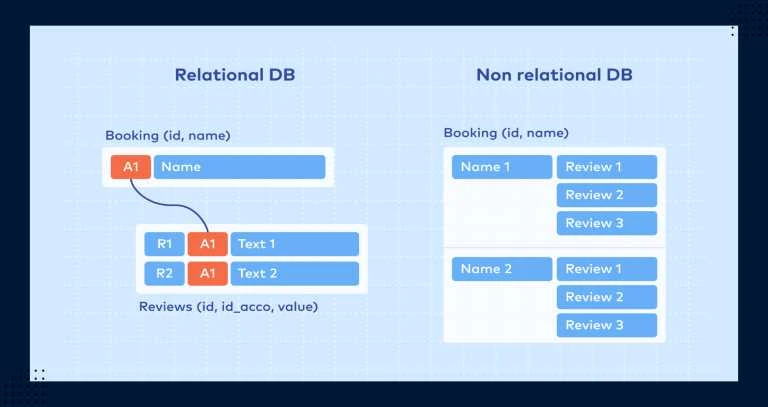
Relational and non-relational databases are two different types of databases that store and manage data in distinct ways. Let’s explore how each type works with examples.
Relational Database:
A relational database is structured around the concept of tables, where data is stored in rows and columns. These tables are related to each other through defined relationships, usually based on common fields or keys. The most common query language used for relational databases is SQL (Structured Query Language).
How it works:
- Tables: Data is organized into tables, where each row represents a record and each column represents a specific attribute or field of that record.
- Schema: A schema defines the structure of the database, specifying the tables, their columns, data types, and relationships.
- Primary Keys: Each table typically has a primary key, a unique identifier for each record in that table.
- Foreign Keys: These are used to establish relationships between tables. A foreign key in one table refers to the primary key in another table, creating a link between them.
Example: Consider a relational database for a library. You might have two tables: one for books and another for authors.
- Books Table:
BookID Title AuthorID 1 Introduction 1 2 Advanced Topic 2 - Authors Table:
AuthorID AuthorName 1 John Smith 2 Jane Doe
Here, the AuthorID in the Books table is a foreign key referencing the AuthorID in the Author’s table.
Non-Relational Database:
Non-relational databases, also known as NoSQL databases, come in various forms, such as document stores, key-value stores, column-family stores, and graph databases. These databases are designed to handle unstructured or semi-structured data and provide more flexibility in schema design compared to relational databases.
How it works:
- Collections/Tables: Instead of tables, NoSQL databases use collections (in document stores) or other similar structures to organize data.
- Documents/Records: Data is stored as documents, which can be JSON, XML, or other formats. Each document can have a different structure.
- Flexibility: Unlike relational databases, there’s no strict schema enforcement. Documents in the same collection can have different attributes.
- Scalability: NoSQL databases are often designed for horizontal scalability, making them suitable for handling large amounts of data.
Example: Consider a non-relational database for an e-commerce platform. You might have a document store database to store user profiles.
- Users Collection:
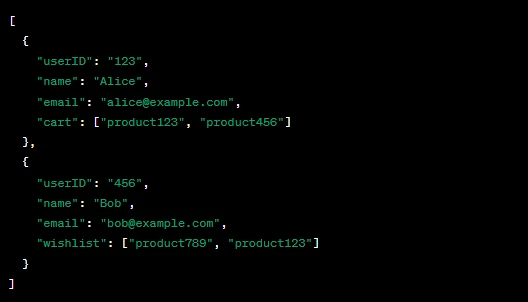
Here, different users have different attributes, and there’s no rigid structure that all documents must adhere to.
In summary, relational databases use structured tables and predefined relationships, while non-relational databases offer more flexibility in data storage and are suitable for handling diverse data structures. The choice between the two depends on the specific needs of your application and the type of data you’re working with.
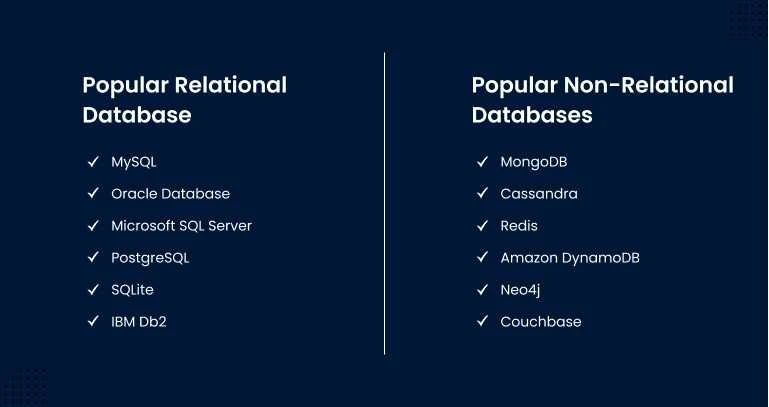
Popular Relational Database
1. MySQL
Overview: MySQL is an open-source relational database management system that has gained widespread popularity due to its performance, reliability, and ease of use. Originally developed by MySQL AB, it is now owned by Oracle Corporation.
Key Features:
- Speed and Performance: MySQL is known for its fast performance, making it suitable for applications with high-velocity workloads and complex queries.
- Scalability: It supports vertical and horizontal scalability to handle growing datasets and user loads.
- Community and Ecosystem: MySQL has a vibrant community that contributes to its development and offers extensive documentation, tutorials, and plugins.
- Wide Platform Support: It runs on various platforms, including Windows, Linux, macOS, and cloud environments.
- ACID Compliance: MySQL ensures data integrity and consistency by supporting ACID (Atomicity, Consistency, Isolation, Durability) transactions.
Use Cases: MySQL is commonly used for web applications, content management systems (CMS), e-commerce platforms, and data-driven applications where a reliable and high-performance database solution is required.
2. Oracle Database
Overview: Oracle Database is a powerful, enterprise-level relational database management system developed by Oracle Corporation. It’s known for its reliability, security features, and support for complex data operations.
Key Features:
- Scalability and Performance: Oracle Database offers advanced features for handling large datasets and demanding workloads, making it suitable for mission-critical applications.
- Advanced Security: It provides robust security features including data encryption, fine-grained access controls, and auditing capabilities.
- Data Management: Oracle Database supports various data types, advanced indexing, and partitioning for efficient data organization and retrieval.
- High Availability: It offers features like Real Application Clusters (RAC) for high availability and failover.
- Business Intelligence: Oracle Database supports analytics, data warehousing, and business intelligence tools for complex reporting and analysis.
Use Cases: Oracle Database is commonly used in enterprise-level applications such as banking, finance, healthcare, and large-scale e-commerce platforms where high performance, security, and scalability are crucial.
3. Microsoft SQL Server
Overview: Microsoft SQL Server is a relational database management system developed by Microsoft. It’s known for its seamless integration with Microsoft technologies and comprehensive set of features.
Key Features:
- Integration: SQL Server integrates well with other Microsoft products, such as Windows Server, Azure, and Power BI.
- Business Intelligence: It includes built-in support for data warehousing, reporting, and analysis through SQL Server Analysis Services (SSAS) and SQL Server Reporting Services (SSRS).
- Security: SQL Server provides various security features, including encryption, authentication mechanisms, and role-based access controls.
- Ease of Use: It offers a user-friendly interface and tools for database management, development, and administration.
- Scalability: SQL Server can handle both small-scale applications and enterprise-level workloads with its scalability options.
Use Cases: SQL Server is commonly used in environments that rely on Microsoft technologies, such as Windows-based applications, .NET applications, and organizations that require tight integration between databases and other Microsoft tools.
4. PostgreSQL
Overview: PostgreSQL, often referred to as Postgres, is an open-source relational database system known for its extensibility, standards compliance, and advanced features.
Key Features:
- Extensibility: PostgreSQL supports custom functions, data types, and indexing methods, allowing developers to extend their capabilities.
- JSON Support: It provides native support for JSON data types, making it suitable for applications with semi-structured or schema-less data.
- Concurrency: PostgreSQL offers multi-version concurrency control (MVCC), enabling high concurrency and isolation levels.
- Advanced Indexing: It supports various indexing techniques, including B-tree, GIN, GiST, and SP-GiST, for optimizing different types of queries.
- Community and Development: PostgreSQL has an active open-source community that continually contributes to its development and feature enhancements.
Use Cases: PostgreSQL is favored by developers who require flexibility, extensibility, and support for advanced data types. It’s often used in applications that deal with geospatial data, real-time analytics, and complex data structures.
5. SQLite
Overview: SQLite is a self-contained, serverless relational database engine that is embedded within applications. It’s designed for simplicity, lightweight usage, and portability.
Key Features:
- Zero Configuration: SQLite requires minimal setup and configuration, making it easy to integrate into applications.
- Serverless: Unlike traditional client-server databases, SQLite is a file-based database engine that operates directly on the application’s filesystem.
- Cross-Platform: SQLite supports various operating systems and programming languages, making it suitable for cross-platform applications.
- Transactional Support: It offers ACID-compliant transactions for data integrity.
- Embedded Usage: SQLite is commonly used in mobile apps, desktop software, IoT devices, and other applications that need a local, lightweight database.
Use Cases: SQLite is ideal for scenarios where applications need a small, self-contained, and low-overhead database solution. It’s often used for local data storage, caching, and applications that require an embedded database.
6. IBM Db2
Overview: IBM Db2 is a family of data management products that include relational database systems designed for various enterprise-level needs.
Key Features:
- Scalability: Db2 offers features like BLU Acceleration and PureScale for handling large datasets and high-performance workloads.
- Hybrid Cloud Support: It provides tools and features for seamless integration and management of data across on-premises and cloud environments.
- Advanced Analytics: Db2 includes support for advanced analytics, machine learning, and in-database processing.
- Security: It offers data encryption, authentication, and auditing features for data protection.
- Developer Tools: Db2 provides tools and interfaces for database development, administration, and performance optimization.
Use Cases: IBM Db2 is commonly used in organizations that require scalability, hybrid cloud support, and advanced analytics capabilities. It’s well-suited for industries such as finance, healthcare, and retail.
Popular Non-Relational Databases
1. MongoDB
Overview: MongoDB is a widely-used open-source document-oriented NoSQL database. It stores data in JSON-like BSON (Binary JSON) format, allowing for flexible and schema-less data structures.
Key Features:
- Schema Flexibility: MongoDB allows developers to store data with varying structures within the same collection.
- High Scalability: It supports horizontal scaling through sharding, distributing data across multiple servers.
- Rich Query Language: MongoDB’s query language supports filtering, sorting, and aggregation on documents.
- Geospatial Capabilities: It includes built-in support for geospatial indexing and querying.
- Ad Hoc Queries: Developers can perform ad hoc queries without the constraints of a predefined schema.
Use Cases: MongoDB is commonly used in applications requiring flexibility with unstructured or semi-structured data, content management systems, real-time analytics, and applications with rapidly evolving data models.
Want to build your product with the latest technologies MERN stack? Connect With GraffersID
2. Cassandra
Overview: Apache Cassandra is a distributed NoSQL database known for its high availability and ability to handle large amounts of data across multiple nodes and data centers.
Key Features:
- Distributed Architecture: Cassandra’s peer-to-peer architecture ensures high availability and fault tolerance.
- Scalability: It can scale horizontally to accommodate massive datasets and high write and read workloads.
- No Single Point of Failure: Data is replicated across nodes, ensuring data availability even in the event of node failures.
- Tunable Consistency: Cassandra offers tunable consistency levels, allowing developers to balance consistency and availability.
- Column-Family Data Model: Cassandra uses a column-family data model that allows for efficient storage and retrieval of data.
Use Cases: Cassandra is often used in applications requiring high availability, scalability, and fault tolerance, such as time-series data, logging, sensor data, and applications with global distribution.
3. Redis
Overview: Redis is an in-memory data store that can serve as a cache, message broker, and data structure server. It’s known for its high-speed data retrieval and support for various data structures.
Key Features:
- In-Memory Storage: Redis stores data in memory, resulting in lightning-fast read and write operations.
- Data Structures: It supports various data structures like strings, lists, sets, hashes, and sorted sets, making it versatile for different use cases.
- Pub/Sub Messaging: Redis allows for real-time messaging and communication through its publish/subscribe mechanism.
- Persistence Options: It offers different persistence options, allowing data to be stored on disk for durability.
- Caching: Redis is commonly used as a caching solution to accelerate data retrieval in applications.
Use Cases: Redis is suitable for applications requiring high-speed data access, real-time analytics, caching, session management, and real-time messaging.
4. Amazon DynamoDB
Overview: Amazon DynamoDB is a managed NoSQL database service offered by Amazon Web Services (AWS). It’s designed for seamless scalability and low-latency performance.
Key Features:
- Serverless Scaling: DynamoDB automatically scales based on traffic, ensuring consistent performance.
- Key-Value and Document Support: It supports both key-value and document data models.
- Fully Managed: AWS handles tasks like provisioning, patching, and backup, reducing operational overhead.
- Global Tables: DynamoDB allows for multi-region replication, ensuring low-latency access for globally distributed applications.
- Pay-as-You-Go Pricing: Users only pay for the throughput and storage they consume.
Use Cases: DynamoDB is commonly used for web and mobile applications with variable workloads, gaming applications, IoT platforms, and applications requiring seamless scalability.
5. Neo4j
Overview: Neo4j is a graph database designed for managing and querying highly connected data, making it suitable for applications involving relationships and complex data structures.
Key Features:
- Graph Data Model: Neo4j stores data in nodes, relationships, and properties, allowing for efficient representation of relationships between entities.
- Cypher Query Language: Neo4j uses the Cypher query language for expressive and efficient querying of graph data.
- Traversals and Pathfinding: It excels in scenarios where traversing relationships and finding paths between nodes is critical.
- Scalability: Neo4j offers both horizontal and vertical scalability options.
- Real-Time Insights: Neo4j is commonly used for applications that require real-time recommendations, fraud detection, and social network analysis.
Use Cases: Neo4j is used in applications involving social networks, recommendation engines, knowledge graphs, fraud detection, and any scenario where relationships play a vital role.
6. Couchbase
Overview: Couchbase is a distributed NoSQL database that combines the flexibility of JSON data with the power of SQL-like querying. It offers a balance between key-value and document data models.
Key Features:
- Flexible Data Model: Couchbase supports JSON documents with a schema-less design, enabling easy data manipulation.
- Memory-Centric Architecture: It leverages in-memory storage for high-speed operations and offers durability with on-disk persistence.
- N1QL Query Language: Couchbase provides N1QL (pronounced “nickel”), which allows for querying JSON data using SQL-like syntax.
- Cross-Datacenter Replication: It supports replication across multiple data centers for high availability and disaster recovery.
- Caching and Full-Text Search: Couchbase includes features for caching frequently accessed data and performing full-text searches on JSON documents.
Use Cases: Couchbase is suitable for applications requiring high-speed data access, real-time analytics, caching, search capabilities, and scenarios where a flexible data model is essential.
Difference Between Rational vs Non Relational Databases
Here’s a comparison table highlighting the key differences between relational and non-relational databases:
| Aspect | Relational Databases | Non-Relational Databases |
|---|---|---|
| Data Model | Structured, uses tables with predefined schemas. | Flexible, supports various data models like key-value, document, and graph. |
| Schema | Fixed schema, requires a predefined structure for data. | Schema-less or dynamic schema allows evolving data structures. |
| Data Integrity | Enforced using constraints and foreign keys. | Relaxed integrity, allows flexible data input and changes. |
| Query Language | SQL (Structured Query Language) for complex queries. | Varies by database type, and uses custom query languages or APIs. |
| Transactions | Strong ACID compliance for data consistency and integrity. | Eventual consistency models prioritize availability over immediacy. |
| Scalability | Vertical scaling can be limiting; horizontal scaling is complex. | Designed for horizontal scalability across distributed nodes. |
| Data Relationships | Established using primary and foreign keys. | Various methods for establishing relationships, like references or nesting. |
| Use Cases | Well-suited for structured data with complex relationships. | Ideal for unstructured, semi-structured data and high-volume workloads. |
| Performance | Complex queries may impact performance at scale. | Optimized for high-speed data retrieval and write operations. |
| Flexibility | Less flexible for evolving data needs. | Highly flexible, accommodating diverse data formats. |
| Examples | MySQL, PostgreSQL, Microsoft SQL Server, Oracle. | MongoDB, Cassandra, Redis, Neo4j, Couchbase, Amazon DynamoDB. |
Pros and Cons of Rational vs Non-Relational Databases
Relational Databases:
Pros:
- Structured Data: Relational databases are excellent for storing structured data with well-defined schemas, ensuring data consistency and integrity.
- Data Integrity: They enforce data integrity through constraints and foreign keys, preventing inconsistencies and data anomalies.
- ACID Transactions: Relational databases offer strong transactional support (Atomicity, Consistency, Isolation, Durability), ensuring data reliability.
- Complex Queries: SQL allows for complex queries involving multiple tables, aggregations, and conditional operations.
- Mature Technology: Relational databases have been around for a long time and have a well-established ecosystem of tools, resources, and best practices.
Cons:
- Scalability Challenges: Traditional relational databases can face scalability issues when dealing with massive datasets or high-velocity workloads.
- Schema Changes: Changing database schemas can be complex and time-consuming, requiring careful planning and migration strategies.
- Performance Impact: Complex joins and queries can lead to performance degradation as the database grows.
- Flexibility: They are less suitable for applications with frequently changing or unstructured data requirements.
- Vertical Scaling: Scaling vertically (upgrading hardware) might be costlier and have limitations compared to horizontal scaling.
Non-Relational Databases (NoSQL):
Pros:
- Schema Flexibility: NoSQL databases can handle unstructured, semi-structured, or evolving data structures without a fixed schema.
- Horizontal Scalability: They excel at horizontal scaling across distributed nodes, providing seamless performance as data volume grows.
- High Performance: NoSQL databases are optimized for high-speed read and write operations, making them suitable for real-time applications.
- Variety of Data Models: NoSQL databases offer diverse data models, such as key-value, document, column-family, and graph.
- Agility and Rapid Development: Schema-less design allows for agile development and quick iteration.
- Eventual Consistency: Some NoSQL databases offer eventual consistency models, prioritizing availability and partition tolerance.
Cons:
- Data Integrity: Maintaining data consistency across distributed nodes can be challenging, leading to potential data conflicts.
- Query Complexity: Complex queries spanning multiple data models might require custom implementation, resulting in increased complexity.
- Learning Curve: Different databases have different query languages and APIs, which may require learning new skills.
- Limited Transactions: Not all NoSQL databases provide strong ACID transactions, which might be crucial for some applications.
- Less Maturity: While NoSQL databases have gained popularity, some may lack the maturity and well-established ecosystems of relational databases.
The choice between a relational and a non-relational database depends on your project’s requirements, data structure, scalability needs, and the trade-offs you’re willing to make. Relational databases offer strong consistency and are suitable for structured data with complex relationships. Non-relational databases provide flexibility, scalability, and performance advantages, making them a better fit for unstructured or evolving data, high-velocity applications, and scenarios where schema changes are frequent. Understanding these pros and cons will help you make an informed decision that aligns with your project’s goals.
When to use relational vs Non Relational databases
The decision to use a relational or non-relational database depends on various factors related to your application’s requirements, data structure, scalability needs, and more. Here are scenarios that can help guide your choice between the two:
Use Relational Databases When:
- Structured Data with Complex Relationships: If your application deals with structured data and requires complex relationships between different entities, a relational database can ensure data integrity and enforce relationships through constraints.
- Transactions and Data Integrity: Relational databases are suitable for applications where data consistency, integrity, and strong ACID-compliant transactions are critical, such as financial systems.
- Well-Defined Schema: If your data model is stable and well-defined, a relational database with a fixed schema can provide a clear structure for your data.
- Complex Queries: Relational databases excel at handling complex queries involving joins, aggregations, and conditional operations across multiple tables.
- Data Reporting and Analytics: If your application requires extensive reporting, business intelligence, and complex analytics, relational databases with SQL capabilities might be more suitable.
- Mature Ecosystem: If you need a well-established ecosystem of tools, libraries, and best practices, relational databases offer a mature and proven technology.
Use Non-Relational Databases When:
- Unstructured or Semi-Structured Data: Non-relational databases are ideal for applications dealing with unstructured, semi-structured, or evolving data formats, such as social media feeds or sensor data.
- Scalability and High Performance: If your application anticipates handling massive amounts of data with high read and write throughput, non-relational databases designed for horizontal scaling can be a better choice.
- Flexible and Agile Development: Non-relational databases allow for schema-less or dynamic schema designs, enabling agile development and easy accommodation of changing data requirements.
- Variety of Data Models: Different types of non-relational databases (document, key-value, column-family, graph) cater to various data storage needs, offering versatility in handling different data structures.
- Real-Time Applications: Non-relational databases are well-suited for real-time applications requiring rapid data access and response times, such as real-time analytics and IoT platforms.
- Global Distribution: When your application needs to replicate data across multiple regions or data centers for low-latency access, some non-relational databases offer features for multi-region replication.
How To Start Building A Database
Starting to build a database involves a series of steps that encompass planning, design, implementation, and testing. Here’s a step-by-step guide to help you get started:
1. Define Your Requirements:
Before you begin, you need a clear understanding of your application’s requirements. Determine what type of data you’ll be storing, how it will be used, the relationships between different data entities, and any specific functionalities you need.
2. Choose the Database Type:
Based on your requirements, decide whether a relational or non-relational database suits your needs better. Consider factors like data structure, scalability, performance, and complexity of queries.
3. Design the Database:
Designing the database involves creating a blueprint for how your data will be structured. For relational databases, this means defining tables, columns, keys, and relationships. For non-relational databases, you’ll determine the data model (e.g., document, key value) and how data will be organized.
4. Create a Data Model:
For relational databases, create an Entity-Relationship Diagram (ERD) to visualize the relationships between different entities. For non-relational databases, decide on the structure of your data documents or entities.
5. Choose a Database Management System (DBMS):
Select the specific database management system that aligns with your chosen database type and your technology stack. Some popular choices include MySQL, PostgreSQL, MongoDB, Cassandra, and Redis.
6. Implement the Database:
This involves actually creating the database using the chosen DBMS. For relational databases, you’ll create tables, define columns and data types, and set up relationships. For non-relational databases, you’ll create collections or buckets and define the structure of your data documents.
7. Develop the Database Schema:
If you’re using a relational database, define the schema by creating tables, specifying primary and foreign keys, and setting up constraints. This step enforces data integrity and relationships.
8. Populate the Database:
Insert initial data into your database to test its functionality. This might involve writing SQL scripts or using tools provided by the DBMS.
9. Implement Data Access Logic:
Depending on your application, you’ll need to implement the code that interacts with the database. This involves creating CRUD (Create, Read, Update, Delete) operations and any additional business logic.
10. Testing and Optimization:
Thoroughly test your database to ensure that data is being stored and retrieved correctly. Test different scenarios, edge cases, and performance under load. Optimize queries and indexes for efficient data retrieval.
11. Backup and Recovery:
Implement regular backup and recovery strategies to ensure that your data is safe in case of failures or disasters. Set up automated backups and practice recovery scenarios.
12. Security and Permissions:
Implement security measures to protect your data. Define roles and permissions to control who can access and modify the data.
13. Documentation:
Create documentation that explains the database schema, data model, relationships, and any specific implementation details. This will be valuable for future developers and maintenance.
14. Deployment:
Deploy your application and database to the production environment. Monitor performance and ensure that everything is functioning as expected.
15. Maintenance and Iteration:
Regularly maintain and optimize your database as your application evolves. Consider updates, schema changes, and performance improvements over time.
Remember that building a database is an iterative process. You might need to revisit and refine your design as you gain a better understanding of your application’s needs and usage patterns.
Choosing the Right Database: Relational vs Non Relational
The choice between relational and non-relational databases depends on the nature of your application, the scale of data you’re dealing with, and your performance requirements. Here are a few scenarios where one type might be favored over the other:
Choose Relational Databases When:
- Your data is structured and adheres to a fixed schema.
- Transactions and data integrity are crucial, such as in financial applications.
- Complex queries involving multiple tables are common.
- Your application has well-defined and stable requirements.
Choose Non-Relational Databases When:
- Your data is unstructured, semi-structured, or constantly evolving.
- Horizontal scalability is a primary concern due to massive amounts of data.
- Rapid development and agile iteration are essential.
- Your application deals with real-time data, like social media feeds or IoT streams.
Conclusion
The debate between relational and non-relational databases isn’t about declaring one as superior to the other; rather, it’s about selecting the right tool for the job. Relational databases excel in maintaining data integrity and handling complex queries, while non-relational databases shine in scenarios requiring massive scalability and flexibility with data models. Understanding your application’s requirements and the strengths of each database type will empower you to make the optimal choice for your data storage needs.

Ready to Transform Your Vision Into Reality?
If you’re looking to bring your website or app idea to life, or if you’re in search of talented developers to drive your next project forward, look no further. At GraffersID, we specialize in turning concepts into exceptional digital experiences. Our team of skilled developers is here to collaborate, innovate, and deliver results that exceed your expectations. Don’t wait to see your dreams take shape – connect with GraffersID today and let’s embark on this exciting journey together. Your success is our commitment.


