
A customer calls your support line. Before they type a single word or answer a single security question or speak to an agent, they’re already verified. The system recognized their voice.
That’s not a futuristic pitch. That’s what banks, healthcare platforms, and AI-driven apps are actively deploying today to verify users, personalize experiences, and reduce friction in digital interactions.
Voice recognition technology has quietly crossed an important threshold. What once powered voice assistants in consumer devices is now evolving into something far more strategic: a biometric identity layer and a natural interface for modern software systems.
For CTOs, product leaders, and founders building AI-powered platforms, this shift is bigger than convenience. As software becomes more conversational and intelligent, companies are starting to design products that respond not only to what users say but also to who is speaking.
In this guide, we break down what voice recognition really is, how it works inside modern AI systems, where businesses are using it today, and when it makes strategic sense to implement it in digital products.
What is Voice Recognition?
Voice recognition is an artificial intelligence technology that identifies or verifies a person based on the unique characteristics of their voice. Instead of analyzing the meaning of spoken words, the system focuses on who is speaking by examining distinctive vocal patterns.
Each human voice contains subtle biometric markers like pitch, frequency, tone, cadence, and vocal tract characteristics that remain relatively consistent over time. AI models analyze these patterns and convert them into a digital identity profile known as a voiceprint.
Voice recognition enables systems to:
- authenticate a user without passwords
- identify callers in customer service systems
- personalize AI assistants based on the speaker
For many industries, voice recognition is becoming a frictionless authentication method that improves both security and user experience.
Voice Recognition vs. Speech Recognition: What’s the Difference?
Many product teams and business leaders use voice recognition and speech recognition interchangeably. In reality, they solve two very different problems in AI systems.
Understanding this difference is important when designing voice-enabled products, because each technology supports a different layer of functionality.
-
Voice recognition focuses on identifying the speaker.
-
Speech recognition focuses on understanding the spoken words.
Modern AI applications often combine both technologies to create secure and conversational user experiences.
| Technology | What It Detects | How It Works | Use Cases |
|---|---|---|---|
| Voice Recognition | Identifies who is speaking based on voice biometrics | Analyzes unique vocal characteristics such as pitch, tone, and speech patterns to create a voiceprint | Identity verification, fraud prevention, biometric login, call center customer identification |
| Speech Recognition | Interprets what is being said in spoken language | Converts spoken audio into text using AI language models and acoustic analysis | Voice assistants, dictation software, voice commands, meeting transcription |
By combining both technologies, companies can create systems that are more secure, easier to use, and faster for customers to interact with.
How Does Voice Recognition Work?
From a technical perspective, voice recognition systems follow a structured processing pipeline. Below is a simplified breakdown of how most modern AI-powered voice recognition systems work.
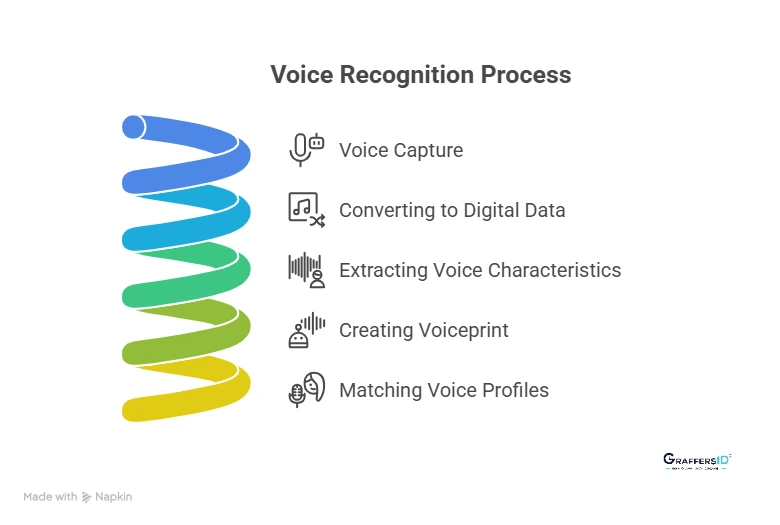
1. Voice Capture
The process begins when a device records a user’s voice through a microphone. This could happen on smartphones, laptops, smart speakers, or customer support call systems.
The system captures the audio signal in real time so it can immediately begin processing the voice input.
2. Converting the Voice Into Digital Data
Human speech is naturally an analog signal. Before AI systems can analyze it, the audio must be converted into digital data.
This conversion transforms sound waves into numerical data that machine learning models can process and analyze for patterns.
3. Extracting Unique Voice Characteristics
Once the audio becomes digital, AI algorithms analyze the voice to extract unique acoustic features. These include patterns that naturally differ between individuals. Common characteristics analyzed include:
- pitch and tone variations
- speech rhythm and pacing
- vocal resonance patterns
- pronunciation and articulation habits
Together, these characteristics help the system distinguish one person’s voice from another.
4. Creating a Voiceprint (Digital Voice Identity)
After analyzing the voice features, the system generates a voiceprint, which acts as a biometric representation of the speaker’s voice.
A voiceprint is similar to a fingerprint but built from audio characteristics. It becomes the reference profile used to identify or verify that person in future interactions.
5. Matching the Voice With Stored Profiles
When the user speaks again, the system compares the new voice sample against stored voiceprints. Based on this comparison, the system can determine whether the voice:
- matches a known user
- belongs to a new speaker
- shows patterns that may indicate spoofing or fraud
Modern AI systems can complete this matching process within milliseconds, enabling real-time authentication and voice-based personalization.
Types of Voice Recognition Systems
Voice recognition systems are typically designed in two different ways, depending on the authentication method and user interaction required.
Understanding these two models helps businesses choose the right approach when implementing voice-based identity verification or AI-powered voice interfaces.

1. Text-Dependent Voice Recognition
Text-dependent voice recognition requires users to repeat a predefined phrase during authentication. Because the system knows the expected words, it can analyze both the spoken phrase and the voice characteristics, which often improves verification accuracy.
Example prompt: “Please say: My voice is my password.”
This approach is commonly used in situations where security and consistency are important, such as:
- banking authentication systems
- secure enterprise access
- phone-based identity verification
Since the system compares both the phrase and the speaker’s voiceprint, text-dependent models are often faster to deploy and easier to train than more complex voice recognition systems.
2. Text-Independent Voice Recognition
Text-independent voice recognition can identify a speaker regardless of what they say. The system focuses entirely on the biometric patterns of the voice, rather than the specific words spoken.
This allows users to interact naturally without repeating scripted phrases. Text-independent systems are commonly used in environments where continuous identification or passive verification is required, such as:
- call center customer identification
- fraud detection systems
- voice analytics and monitoring platforms
Because they rely solely on voice characteristics, these systems are typically more advanced and require larger training datasets, but they enable more seamless and natural user experiences.
Key Technologies Behind Modern Voice Recognition Systems
Modern voice recognition systems are built using a combination of AI models and supporting infrastructure that work together to capture, analyze, and verify human voices in real time.
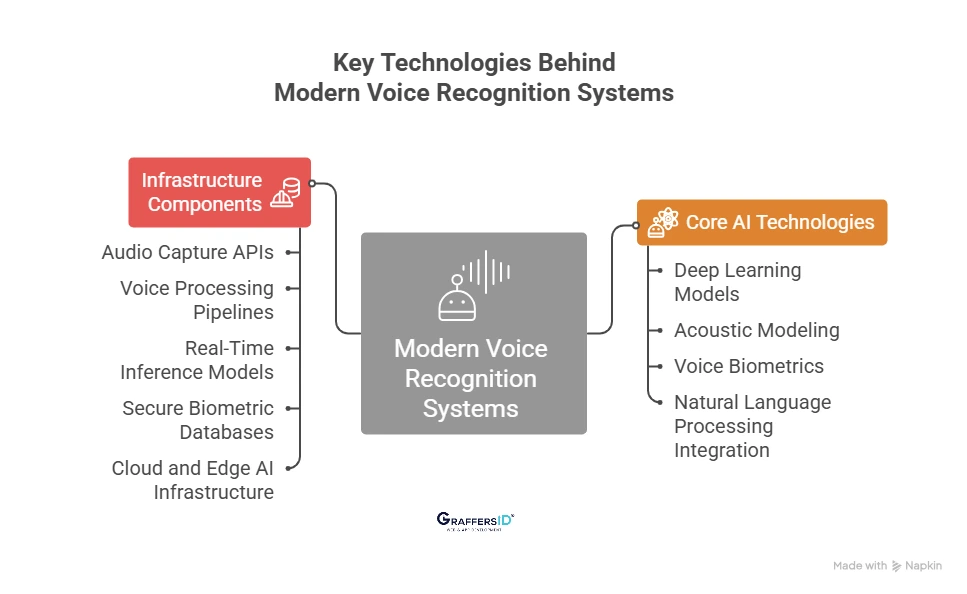
Core AI Technologies Used in Voice Recognition
- Deep Learning Models: Deep neural networks are trained on massive audio datasets to learn patterns in human speech. These models help systems accurately recognize voice characteristics across different accents, tones, and speaking styles.
- Acoustic Modeling: Acoustic models analyze how sound waves form speech patterns. They convert raw audio signals into structured features that AI systems can use to identify unique voice characteristics.
- Voice Biometrics: Voice biometric technology analyzes distinctive vocal traits such as pitch, cadence, resonance, and speech rhythm to create a voiceprint, which functions as a digital identity for the speaker.
- Natural Language Processing (NLP) Integration: In many AI systems, voice recognition works alongside NLP. While voice recognition verifies who is speaking, NLP helps systems understand what the user is saying, enabling conversational AI experiences.
Infrastructure Components That Support Voice Recognition
- Audio Capture APIs: Applications use audio capture APIs to record voice input from devices such as smartphones, laptops, smart speakers, and call center systems.
- Voice Processing Pipelines: These pipelines process raw audio data by cleaning noise, extracting voice features, and preparing the data for AI model analysis.
- Real-Time Inference Models: Inference engines run trained AI models that analyze voice samples instantly and compare them with stored voiceprints for identification or authentication.
- Secure Biometric Databases: Voiceprints are stored in encrypted biometric databases. Security and compliance are critical because voice data is considered sensitive biometric information.
- Cloud and Edge AI Infrastructure: Voice recognition systems often run on cloud platforms for scalability, while edge AI processing is used in devices that require faster responses and reduced latency.
For product teams, the real challenge is not just developing accurate voice recognition models but integrating these components into secure, scalable production systems that work reliably across devices and environments.
How Businesses Are Using Voice Recognition in Real Applications?
Voice recognition is no longer limited to voice assistants or smart speakers. Below are some of the most common ways businesses are using voice recognition in modern digital products.
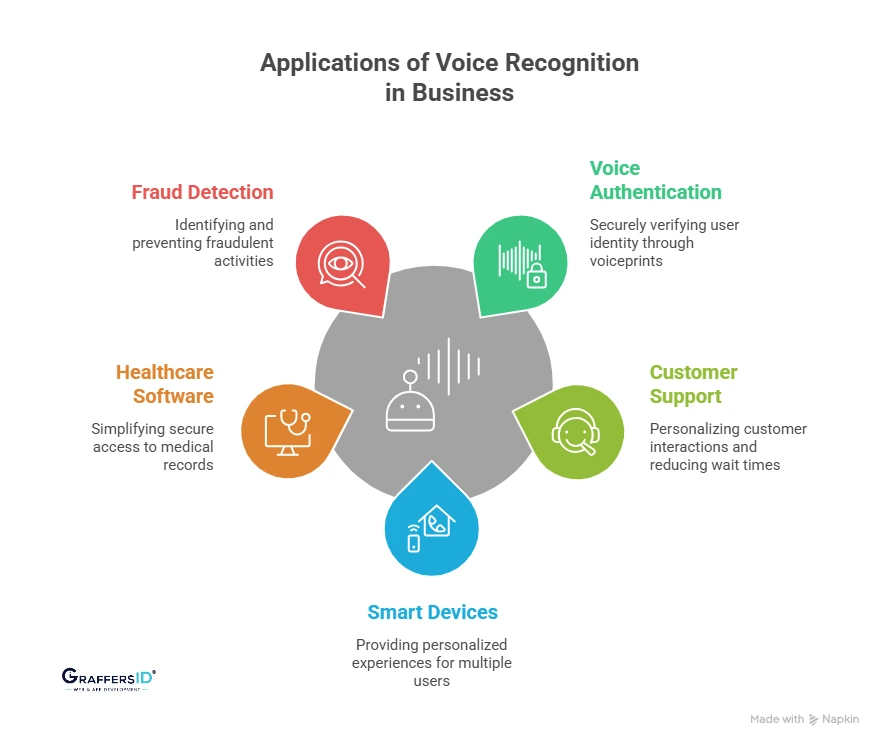
1. Voice Authentication for Passwordless Login
Many organizations are adopting voice recognition as a biometric alternative to passwords and PINs. By verifying a user’s voiceprint, systems can confirm identity instantly without requiring manual credentials. Common examples include:
-
Banking apps verifying customers during phone or app interactions
-
Enterprise platforms enabling secure voice-based login
-
Internal systems allowing employees to access tools without passwords
This approach reduces authentication friction while maintaining strong identity verification.
2. Voice Recognition in Customer Support Systems
Customer service platforms increasingly use voice recognition to identify returning callers automatically. When a customer calls, the system can recognize their voice and retrieve their profile in real time. This allows support systems to:
- retrieve customer account information instantly
- personalize conversations based on previous interactions
- reduce repetitive verification questions
As a result, businesses can shorten support calls and improve the overall customer experience.
3. Smart Devices and IoT Personalization
Voice recognition is widely used in smart devices and connected ecosystems to identify different users within the same environment. For example, smart home platforms can recognize individual household members and deliver personalized responses such as:
- customized device preferences
- personalized music or content recommendations
- user-specific home automation routines
This enables shared devices to provide individualized experiences for multiple users.
4. Voice Identity Systems in Healthcare Software
Healthcare platforms are adopting voice recognition to simplify secure access to sensitive medical systems. Doctors and healthcare professionals can use voice-based identity verification to:
- securely access patient records
- authenticate clinical systems
- enable voice-driven documentation and dictation tools
In fast-paced medical environments, reducing login steps helps professionals access critical information faster.
5. Voice-Based Fraud Detection in Financial Services
Financial institutions increasingly use voice recognition as an additional fraud detection layer during customer interactions. AI systems analyze voice patterns to detect risks such as:
- impersonation attempts
- voice spoofing attacks
- suspicious behavioral anomalies
By identifying irregular voice patterns in real time, organizations can prevent fraud while maintaining a smooth customer experience.
Key Benefits of Voice Recognition in Digital Products
Voice recognition is not just a new interface feature. It offers the following benefits to digital products:
- Stronger Security Without Passwords: Voice recognition enables biometric authentication based on unique voice patterns. This allows users to verify their identity without remembering passwords, reducing security risks while making login and verification processes faster.
- Faster and Hands-Free User Interactions: Voice-based interaction allows users to perform tasks without typing or navigating complex interfaces. This is especially useful in mobile environments, customer support systems, and workplace tools where speed and efficiency matter.
- More Personalized User Experiences: By identifying who is speaking, voice recognition allows applications to deliver personalized responses, recommendations, and settings. This helps businesses create software experiences that adapt automatically to individual users.
- Improved Accessibility for a Wider Range of Users: Voice interfaces make digital products easier to use for people who may struggle with traditional input methods like typing or touchscreen navigation. As a result, voice technology plays an important role in building more accessible and inclusive software.
How Can Businesses Implement Voice Recognition in Their Products?
For most organizations, the biggest mistake is starting with the technology instead of the problem. Successful voice recognition implementations begin with a clear business objective, followed by the right architecture and system integration strategy.
Below is a practical framework many product teams use when introducing voice recognition into real-world software systems.
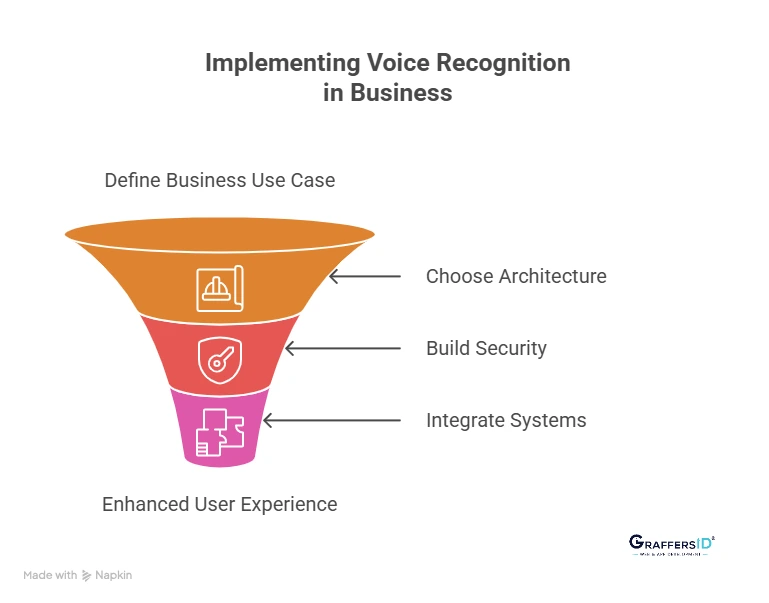
1. Start With a Clear Business Use Case
Voice recognition delivers the most value when it solves a specific workflow problem rather than being added as a novelty feature. Common high-impact use cases include:
- reducing login and authentication friction
- automating identity verification in customer support
- enabling hands-free interaction in mobile or field environments
Defining the use case early helps teams avoid unnecessary complexity and ensures the technology delivers measurable value.
2. Choose the Right Voice Recognition Architecture
Once the use case is defined, the next step is selecting an architecture that fits the product’s scale and security requirements. Organizations typically choose between:
- Cloud-based voice APIs for faster implementation and scalability
- Hybrid AI architectures that combine cloud models with local processing
- Custom voice recognition models for high-security or specialized applications
The right architecture depends on factors such as data sensitivity, performance requirements, and integration with existing systems.
3. Build Secure Voice Data Pipelines
Voice recognition systems process biometric data, which means security and compliance must be built into the architecture from the start. Most production systems include safeguards such as:
- encrypted voice data storage
- secure voice processing pipelines
- privacy-compliant data management policies
Strong security practices protect user identity while helping organizations meet regulatory and compliance requirements.
4. Integrate Voice Recognition With Existing Business Systems
Voice recognition rarely creates value as a standalone feature. Its real impact comes from integrating it into the tools businesses already use. Common integration points include:
- CRM systems for customer identification
- customer support platforms for faster verification
- mobile applications and web platforms
- internal enterprise software
In practice, integration is often the most complex part of implementation, but it is also where voice recognition delivers the greatest operational and user experience benefits.

Conclusion: Voice Recognition is Becoming a Core Layer of Intelligent Software
Voice recognition is rapidly moving beyond its early role in consumer assistants and smart devices. Today, it is emerging as a strategic capability for identity verification, personalization, and AI-driven automation in modern digital products.
As organizations invest more in intelligent systems, voice is becoming an important interface that allows users to interact with software in a faster and more natural way. Companies implementing voice recognition effectively are using it to improve customer experience, strengthen biometric security, and enable more natural human-AI interactions.
For CTOs, founders, and product leaders building AI-powered platforms, voice recognition is no longer just an experimental feature. It is increasingly becoming part of the core architecture of intelligent applications, especially in industries where security, personalization, and customer experience are critical.
As voice technology continues to mature, businesses that integrate it thoughtfully into their products will be better positioned to create more intuitive, secure, and scalable digital experiences.
At GraffersID, we help startups and enterprises design and build AI-powered software, intelligent automation systems, and scalable web and mobile products using experienced developers and modern technology frameworks.
Hire expert AI developers to build secure, production-ready AI solutions tailored to your business goals.


