
Voice has become one of the most valuable and fastest-growing data sources in modern digital products. Every customer support call, virtual meeting, voice command, and AI agent interaction produces spoken data that holds insights businesses can no longer afford to ignore.
Speech-to-Text (STT) technology transforms this voice data into structured, searchable, and machine-readable text. What started as a simple transcription has evolved into a core AI capability that powers automation, analytics, conversational interfaces, and intelligent decision-making at scale.
In 2026, Speech-to-Text is no longer a “nice-to-have” feature. It is a foundational layer for AI-first products, enabling real-time insights, voice-driven workflows, and enterprise intelligence across industries, from customer support and healthcare to SaaS platforms and AI agents.
In this guide, you’ll discover:
-
What Speech-to-Text means in modern AI systems
-
How AI converts voice into text, step by step
-
The different types of Speech-to-Text solutions used by businesses
-
Practical, real-world use cases across industries
-
How to choose the right Speech-to-Text solution for your product or enterprise?
What is Speech-to-Text?
Speech-to-Text (STT) is an artificial intelligence technology that automatically converts spoken language into written text. It uses advanced machine learning models and speech recognition algorithms to understand human speech and transform audio input into accurate, readable text.
Also known as Automatic Speech Recognition (ASR), Speech-to-Text is widely used in modern applications such as voice assistants, customer support systems, meeting transcription tools, and AI agents.
At its core, Speech-to-Text systems analyze audio signals, break speech into sound patterns, and match them with language models to produce text that can be:
-
Stored and searched
-
Analyzed for insights
-
Integrated into automation workflows
-
Used by AI systems for further understanding and action
In 2026, Speech-to-Text has evolved beyond basic transcription. Modern STT solutions are context-aware, support multiple languages and accents, and integrate seamlessly with large language models to deliver higher accuracy and real-time intelligence.
Read More: What is Text-to-Speech (TTS)? How It Works, Benefits, Applications & AI Trends in 2026
Speech-to-Text vs. Voice Recognition vs. Natural Language Processing
These terms are often used interchangeably, but they serve different purposes in AI systems. Understanding the distinction helps businesses choose the right technology.
1. Speech-to-Text
-
Converts spoken words into written text
-
Focuses on what is being said
-
Acts as the entry point for voice-based AI workflows
2. Voice Recognition
-
Identifies who is speaking
-
Used for speaker authentication and personalization
-
Often combined with Speech-to-Text in secure systems
3. Natural Language Processing (NLP)
-
Understands the meaning and intent of text
-
Powers chatbots, sentiment analysis, and AI decision-making
-
Operates on text generated by Speech-to-Text systems
In modern AI-powered products, these technologies work together in a pipeline. Speech-to-Text is the first critical step, enabling voice data to be converted into text that NLP models and AI agents can understand, analyze, and act upon.
How Does Speech-to-Text Work in 2026?
Modern Speech-to-Text systems use deep learning, transformer-based models, and large language models (LLMs) to accurately convert human speech into written text. Unlike older rule-based systems, today’s AI-driven Speech-to-Text solutions are designed to understand context, accents, and real-world speech patterns.
Here’s how the Speech-to-Text process works, step by step:
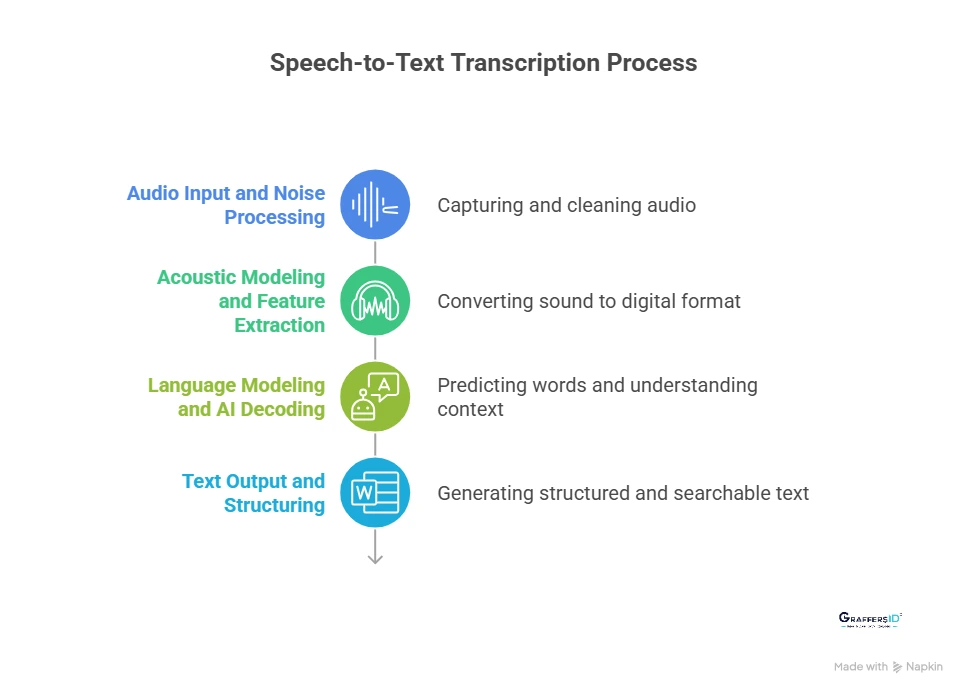
1. Audio Input and Noise Processing
The process starts by capturing audio from different sources, such as:
-
Microphones
-
Phone calls and video meetings
-
Uploaded audio or video recordings
Before transcription begins, the system cleans the audio by:
-
Reducing background noise
-
Normalizing volume and sound levels
-
Separating speech from silence or interruptions
This step is essential for improving transcription accuracy, especially in real-world environments like customer support calls, online meetings, or public spaces.
2. Acoustic Modeling and Feature Extraction
Once the audio is cleaned, the system converts sound waves into a digital format that AI models can analyze. At this stage:
-
Speech is broken down into small sound units called phonemes
-
Acoustic features such as pitch, tone, and frequency are extracted
-
Deep learning models analyze these features to recognize speech patterns
Modern acoustic models are trained on millions of hours of multilingual and accented speech, allowing them to handle variations in pronunciation, speaking speed, and background conditions.
3. Language Modeling and AI Decoding
After identifying sound patterns, the system determines what words are being spoken. This is done by:
-
Predicting the most likely words based on recognized speech sounds
-
Applying grammar rules and contextual understanding
-
Using LLM-powered language models to interpret meaning within sentences
This step is where modern Speech-to-Text systems significantly outperform older technologies. By understanding context, AI models can reduce errors, handle ambiguous phrases, and generate more natural and accurate transcriptions.
4. Text Output and Structuring
In the final step, the system generates structured text that is ready for business use. This includes:
-
Adding punctuation and capitalization
-
Identifying different speakers in conversations
-
Attaching timestamps and confidence scores where needed
The final output is clean, searchable, and formatted for downstream use, such as analytics, automation workflows, AI agents, documentation, or compliance records.
Types of Speech-to-Text Solutions for Business Use Cases in 2026
Not all Speech-to-Text solutions are designed for the same business needs. In 2026, companies choose Speech-to-Text systems based on speed, accuracy, deployment model, privacy requirements, and scalability.
Below are the most common types of Speech-to-Text solutions used in real-world business applications.
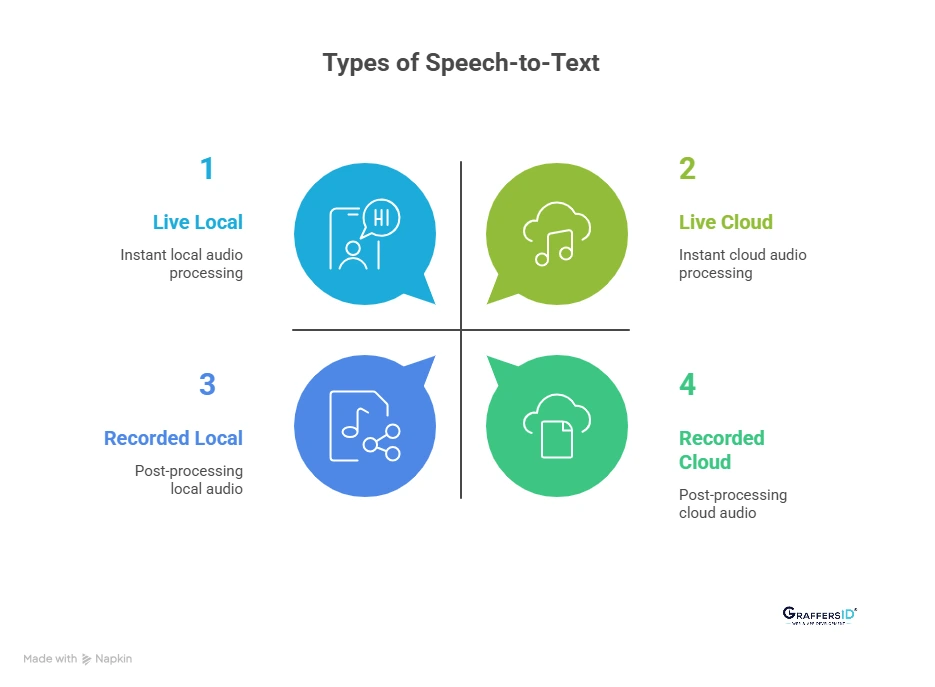
1. Real-Time Speech-to-Text (Live Transcription)
Real-time Speech-to-Text converts spoken words into text instantly as the audio is being spoken. This type of solution is commonly used when immediate insights or actions are required.
Key Features of Real-Time Speech-to-Text:
-
Converts speech into text with minimal latency
-
Supports live conversations and continuous audio streams
-
Often integrated with AI agents and conversational systems
Common Use Cases of Real-Time Speech-to-Text:
-
Customer support calls and contact centers
-
Virtual meetings and live webinars
-
Voice assistants and AI-powered chat or voice agents
-
Real-time monitoring and decision-support systems
Real-time Speech-to-Text is essential for businesses building voice-first experiences or AI agents that must listen and respond instantly.
2. Batch Speech-to-Text (Recorded Audio Transcription)
Batch Speech-to-Text processes prerecorded audio or video files instead of live streams. This approach prioritizes accuracy and post-processing quality over speed.
Key Features of Batch Speech-to-Text:
-
Processes audio files after recording
-
Allows deeper analysis and refinement
-
Supports punctuation, speaker labels, and timestamps
Common Use Cases of Batch Speech-to-Text:
-
Podcast and video transcription
-
Interviews and research recordings
-
Training data generation for AI models
-
Compliance and audit documentation
Batch Speech-to-Text is ideal when businesses need high-quality transcripts for analysis, storage, or regulatory purposes.
3. Cloud-Based Speech-to-Text Solutions
Cloud-based Speech-to-Text systems run on scalable cloud infrastructure and are accessed through APIs. They are the most widely adopted option for modern digital products.
Key Features of Cloud-Based Speech-to-Text:
-
Highly scalable and cost-efficient
-
Easy integration with web and mobile applications
-
Continuous model improvements and updates
Common Use Cases of Cloud-Based Speech-to-Text:
-
SaaS platforms and enterprise applications
-
Startups launching AI-powered features quickly
-
Applications with fluctuating usage volumes
Cloud-based Speech-to-Text is best suited for businesses that need fast deployment, global scalability, and flexibility.
4. On-Device Speech-to-Text Solutions
On-device Speech-to-Text runs directly on user devices without sending audio to external servers. This approach focuses on privacy, security, and low latency.
Key Features of On-Device Speech-to-Text:
-
Processes speech locally on the device
-
Works with limited or no internet connectivity
-
Reduces data transfer and privacy risks
Common Use Cases of On-Device Speech-to-Text:
-
Healthcare and legal applications
-
Regulated industries with strict data policies
-
Offline-capable mobile and edge devices
On-device Speech-to-Text is increasingly important for businesses prioritizing data control and compliance.
Use Cases of Speech-to-Text for Businesses Across Industries in 2026
In 2026, organizations across industries rely on Speech-to-Text to turn voice data into actionable intelligence.
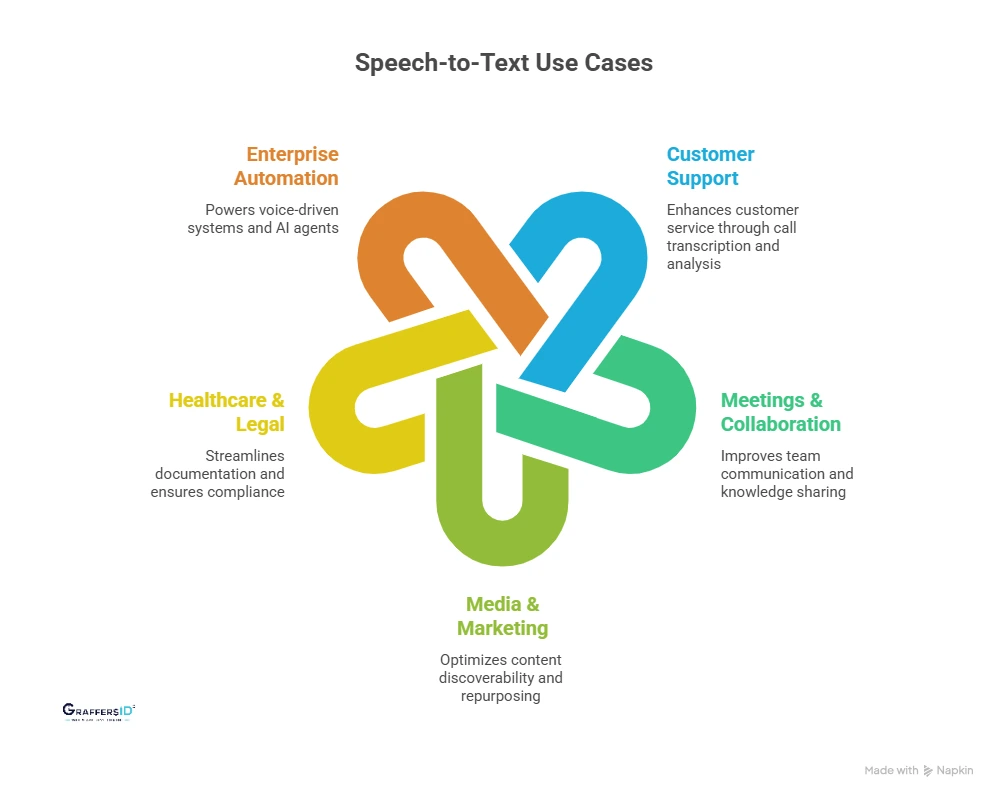
- Customer Support and Contact Centers: Speech-to-Text enables automatic transcription of customer calls, allowing businesses to analyze conversations at scale. By combining transcripts with AI-driven sentiment analysis and quality monitoring, support teams can reduce handling time, improve customer satisfaction, and optimize agent performance.
- Healthcare and Legal Documentation: In healthcare and legal industries, Speech-to-Text streamlines documentation by converting spoken notes into structured records. This reduces administrative workload while maintaining accuracy, compliance, and consistency across critical documentation processes.
- Meetings, Calls, and Team Collaboration: Speech-to-Text automatically converts meetings and calls into accurate summaries and searchable transcripts. This improves knowledge sharing, reduces manual note-taking, and ensures important decisions and action items are never lost across distributed teams.
- Media, Content, and Marketing Teams: Speech-to-Text helps convert audio and video content into captions, subtitles, and written assets that are optimized for search engines. This allows marketing teams to repurpose spoken content faster, improve content discoverability, and align with AI-driven search and content indexing.
- Enterprise Automation and AI Agents: Speech-to-Text acts as the input layer for voice-driven automation and AI agents. It enables systems to capture spoken commands, update CRMs, trigger workflows, and power conversational AI that can listen, understand context, and take action in real time.
How to Choose the Best Speech-to-Text Software for Your Business in 2026?
Choosing the right Speech-to-Text solution is not just a technical decision; it directly impacts accuracy, automation efficiency, user experience, and long-term scalability. The ideal system should align with your product goals, industry requirements, and growth plans.
Below are the key factors businesses should evaluate when selecting a Speech-to-Text solution in 2026.
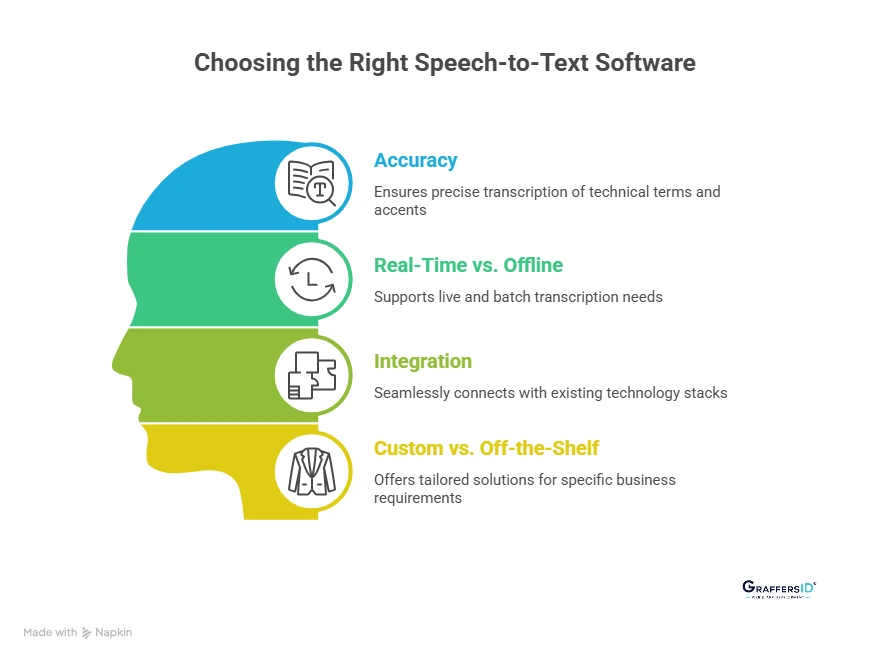
1. Accuracy and Industry-Specific Customization
Speech-to-Text accuracy is the most critical success factor. Generic models often struggle with technical terms, brand names, or industry jargon.
When evaluating a solution, look for:
-
Support for industry-specific vocabulary (healthcare, legal, fintech, SaaS, etc.)
-
Ability to customize or fine-tune models using your own data
-
Consistent performance across different accents, speaking styles, and noisy environments
Higher accuracy reduces manual review, improves automation reliability, and delivers better insights from voice data.
2. Real-Time vs. Offline Speech-to-Text Capabilities
Different business use cases require different transcription speeds and workflows. Choose a solution that supports:
-
Real-time speech-to-text for live calls, meetings, AI agents, and customer support
-
Batch or offline transcription for recorded calls, videos, training data, and compliance archives
The best platforms allow you to use both, enabling flexibility as your product and use cases evolve.
3. Integration, APIs, and Scalability
Speech-to-Text should fit seamlessly into your existing technology stack. Key considerations include:
-
API-first architecture for fast and flexible integration
-
Easy compatibility with web apps, mobile apps, and backend systems
-
Proven ability to scale with user growth, traffic spikes, and increasing audio volumes
A scalable, well-integrated solution ensures long-term performance without frequent re-architecture.
4. Custom vs. Off-the-Shelf Speech-to-Text Solutions
While ready-made tools can work for basic use cases, many businesses see better results with custom implementations. Custom Speech-to-Text solutions offer:
-
Better accuracy through domain adaptation
-
Tighter integration with internal workflows and AI systems
-
Greater control over performance, privacy, and cost optimization
For products built around voice, custom Speech-to-Text implementations often outperform one-size-fits-all tools in both accuracy and business impact.

Conclusion: Why Speech-to-Text is Essential for AI-Driven Products in 2026?
Speech-to-Text has moved far beyond basic transcription. In 2026, it stands as a core AI layer that enables automation, real-time insights, and intelligent conversational experiences across digital products.
Organizations that treat voice data as a strategic asset and integrate Speech-to-Text with AI workflows, analytics, and automation gain faster decision-making, improved customer experiences, and a clear competitive advantage. From AI agents and voice-enabled applications to enterprise automation and data intelligence, Speech-to-Text plays a critical role in how modern systems listen, understand, and act.
As voice interfaces continue to scale, businesses that invest early in reliable, accurate, and well-integrated Speech-to-Text solutions position themselves for long-term growth in an AI-first future.
At GraffersID, we help startups and enterprises hire experienced AI developers who are experts in building AI-powered web and mobile applications and designing scalable AI automation and conversational systems.
Contact us to build scalable AI solutions with GraffersID!



