
In 2026, artificial intelligence is everywhere, powering chatbots, automating workflows, and enabling smarter decision-making across industries. But while large language models (LLMs) like GPT-4 and Gemini Ultra dominate the AI industry with billions of parameters, they are not always the best fit for real-world business needs.
Enter small language models (SLMs), AI systems with 1 million to 10 billion parameters that deliver speed, efficiency, and domain-specific intelligence without requiring massive infrastructure. These models run on laptops, mobile devices, and even edge hardware, making advanced AI accessible to businesses of all sizes.
Unlike their larger counterparts, SLMs are designed for practical deployment. They are faster to fine-tune, cheaper to maintain, and more secure because they can operate on-premises without exposing sensitive data to external servers.
This guide explores how to build small language models in 2026, covering the techniques, tools, and deployment strategies developers need to create AI solutions that are lightweight, powerful, and business-ready.
Read More: What Are LLMs? Benefits, Use Cases, & Top Models in 2026
What Are Small Language Models?

Small language models use the same transformer architecture as LLMs but are optimized to run with fewer parameters and resources. They achieve this through methods such as:
- Knowledge Distillation: transferring knowledge from a large “teacher” model to a smaller “student” model.
- Pruning: removing unnecessary neurons and connections.
- Quantization: lowering numerical precision to reduce memory use and improve inference speed.
Unlike general-purpose LLMs, SLMs are often trained for domain-specific tasks. For example:
- Healthcare: On-device medical chatbots trained on clinical datasets.
- Finance: Fraud detection and compliance monitoring.
- Manufacturing: Edge AI for predictive maintenance.
Why Businesses in 2026 Are Choosing SLMs?
AI adoption is no longer optional for enterprises, but large models create challenges such as:
- High infrastructure and API costs
- Vendor lock-in with proprietary models
- Data security risks when using third-party cloud services
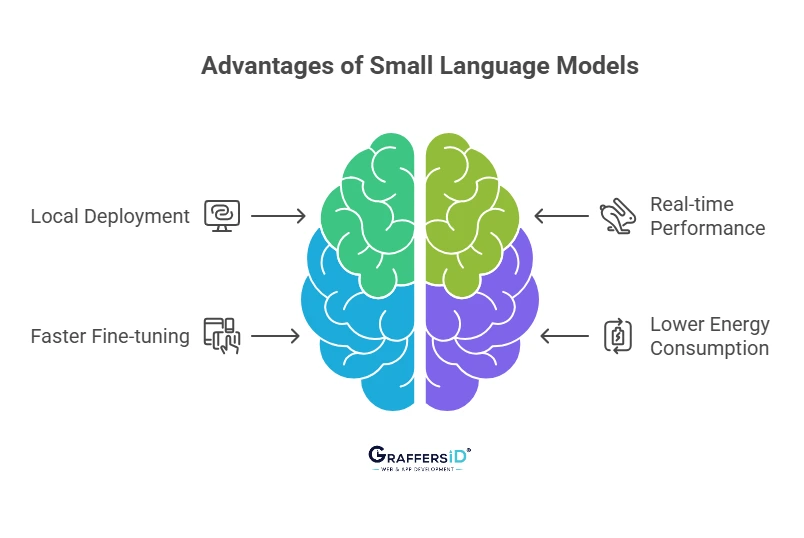
Small language models solve these issues by offering:
- Local deployment on laptops, mobile processors, and consumer GPUs
- Real-time performance with low latency
- Faster fine-tuning for industry-specific datasets
- Lower energy consumption, supporting sustainability initiatives
How to Build a Small Language Model in 2026?
Creating an SLM involves balancing accuracy, efficiency, and scalability.
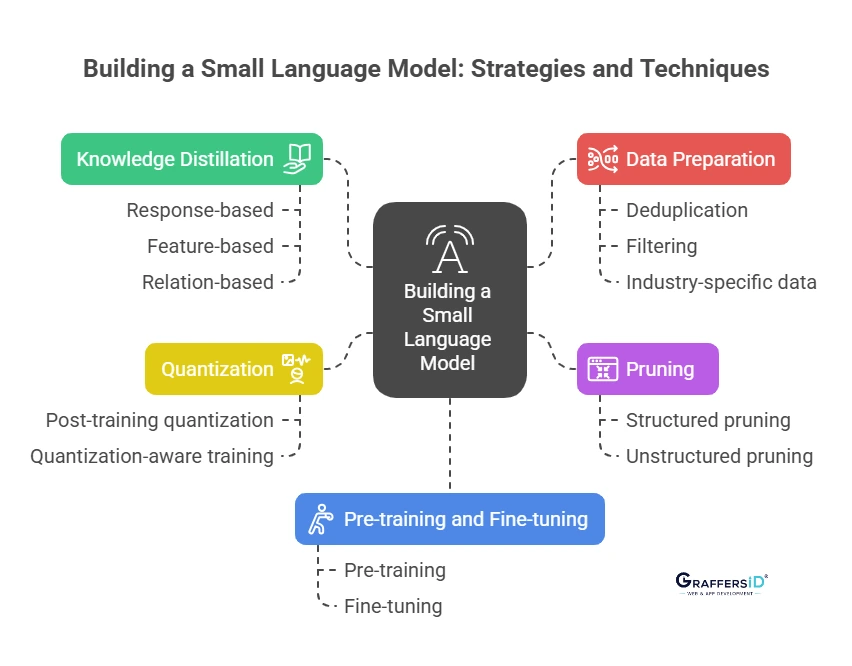
1. Knowledge Distillation
Train a smaller student model to replicate the behavior of a larger teacher model.
- Response-based: Mimic the teacher’s outputs.
- Feature-based: Learn intermediate layer representations.
- Relation-based: Understand embedding relationships.
2. Pruning
Remove redundant parameters to reduce model size.
- Structured pruning: Entire heads or layers removed.
- Unstructured pruning: Selective weight removal.
3. Quantization
Convert model weights from FP32 to INT8 or INT4.
- Post-training quantization (PTQ): Quick conversion.
- Quantization-aware training (QAT): Higher accuracy after quantization.
Read More: Small vs. Large Language Models in 2026: Key Differences, Use Cases & Choosing the Right Model
4. Pre-training and Fine-tuning
- Pre-train on large datasets for general understanding.
- Fine-tune with domain-specific datasets (finance, healthcare, law) for accuracy.
5. Data Preparation
High-quality data is critical. Steps include:
- Deduplication to remove repetition
- Filtering low-quality or irrelevant text
- Using industry-specific data sources
Deploying and Customizing Your Small LLM
SLMs are designed for efficient deployment. With modern tools, they run on everyday hardware.
Tools for Deployment
- Llama.cpp: optimized for CPUs and consumer GPUs.
- GGUF with QLoRA: standard format for quantized models.
- ONNX Runtime: hardware-agnostic deployment.
Key Deployment Parameters (Llama.cpp Example)
- -ngl N → Offload layers to GPU
- -t N → Set thread count
- –temp N → Control output randomness
- -c N → Configure context window size
Deployment Roadmap
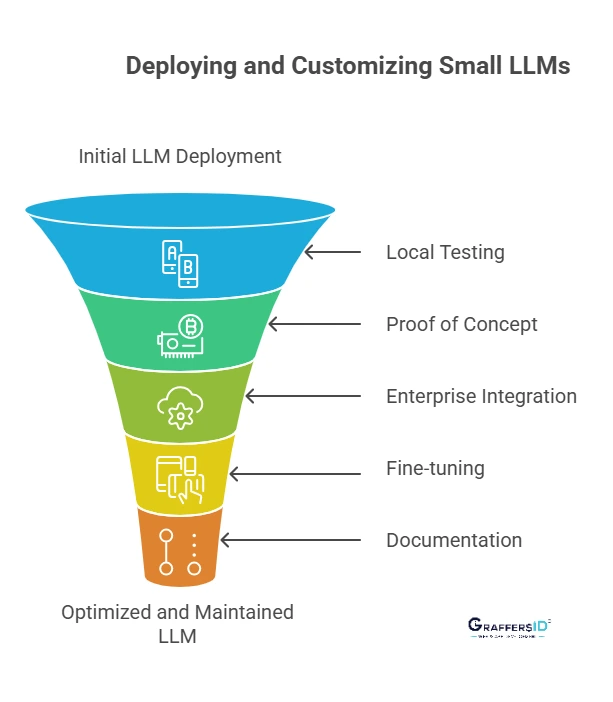
- Local testing on laptops or lightweight servers
- Proof of concept on workstation GPUs (e.g., NVIDIA RTX 4080/4090)
- Enterprise integration across edge devices, private cloud, or hybrid setups
Fine-tuning Techniques
- LoRA (Low-Rank Adaptation): Fine-tunes a small set of parameters.
- QLoRA: Fine-tunes quantized models on consumer-grade GPUs.
- PEFT (Parameter-Efficient Fine-Tuning): Modular fine-tuning without retraining the full model.
Documentation and Maintenance
Maintain detailed records of:
- Training configurations
- Hyperparameters
- Deployment setups
This ensures long-term maintainability and adaptability.

Conclusion
As AI adoption accelerates in 2026, the focus is shifting from “how big a model can get” to “how efficiently it can deliver value.” Small language models (SLMs) prove that innovation is not always about scale, it is about speed, adaptability, and cost-effectiveness. By leveraging techniques such as knowledge distillation, pruning, and quantization, developers can build compact models.
For businesses, the takeaway is clear: choose models that align with your goals and infrastructure, not just the largest available option.
At GraffersID, we specialize in building custom AI solutions, domain-specific small language models, and enterprise AI copilots that run seamlessly across edge devices and hybrid setups.
Ready to explore how a small language model can transform your business in 2026?
Connect with GraffersID today and build AI solutions that deliver real-world results.



