
What if AI could see, hear, and understand the world just like humans?
That’s exactly what Multimodal AI is making possible. The multimodal AI market, valued at $1.2 billion in 2023, is projected to grow at over 30% CAGR, crossing $4.5 billion by 2028. This rapid growth isn’t just a tech buzzword; it signals a fundamental shift in AI adoption across industries.
Unlike traditional AI that relies on a single data type, multimodal AI combines text, images, audio, and video to deliver more natural, human-like, and accurate results. From AI shopping assistants that analyze products visually while answering voice queries to healthcare systems that interpret scans alongside medical notes, its applications are expanding at lightning speed.
Even more striking, what once cost $100,000 to train in 2022 can now be built for under $2,000 in 2026, making it accessible for both startups and global enterprises.
In this blog, we’ll cover:
- How multimodal AI works and why it matters in 2026
- Core components powering these systems
- Real-world use cases in healthcare, retail, insurance, and more
- Key challenges in building and scaling multimodal AI
- Top models and tools every business leader should know
By the end, you’ll understand why multimodal AI is the hidden power behind next-gen applications and how your business can leverage it today.
What is Multimodal AI & Why It Matters in 2026?
Multimodal AI is a type of artificial intelligence that can process and integrate multiple types of data at once: text, images, audio, video, and even sensor data.
Unlike traditional AI, which works with one data type (called unimodal AI), multimodal AI delivers more context-aware, accurate, and human-like interactions.
Example: You upload a desk photo and ask, “Where are my glasses?” The AI processes the image and your question together, then replies, “Your glasses are under the blue notebook on the left.”
Read More: What Are Multi-Modal AI Agents? Features, Enterprise Benefits & Use Cases (2026 Guide)
Key Components of Multimodal AI Systems
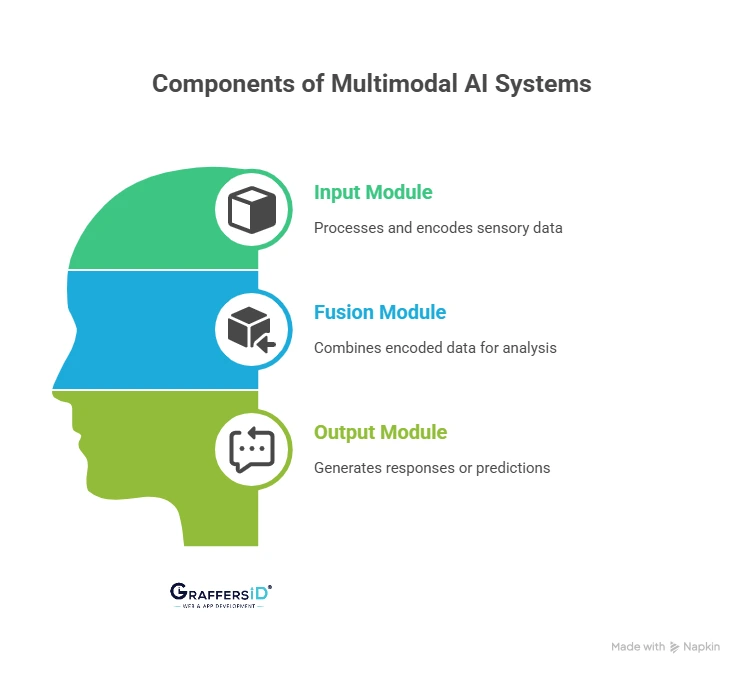
1. Input Module: The AI’s Senses
- Visual encoders: Analyze images and videos.
- Text encoders: Use transformers (like GPT) to understand language.
- Audio processors: Convert sound into spectrograms for analysis.
Each encoder turns real-world data into embeddings (mathematical representations) for the AI to process.
2. Fusion Module: Combining Data
- Early Fusion: Combines raw data right away (powerful, but rigid).
- Mid Fusion: Processes each input separately, then merges (balanced).
- Late Fusion: Processes separately and merges at the decision stage (flexible, but less connected).
3. Output Module: The Final Answer
- Generative Outputs: Create text, images, or voice responses.
- Predictive Outputs: Classify, detect, or predict outcomes (e.g., diagnosing disease, detecting fraud).
Unimodal AI vs. Multimodal AI: What’s the Difference in 2026?

1. Unimodal AI
- Works with a single data type (only text, only image, or only audio).
- Simpler, cheaper, but limited in understanding.
- Great for niche tasks like image classification or text sentiment analysis.
2. Multimodal AI
- Works with multiple data types at once.
- Connects relationships between different inputs for a deeper understanding.
- Offers higher accuracy, context awareness, and error resilience.
This is why multimodal AI is quickly becoming the foundation for generative AI in 2026.
How Multimodal AI Improves Generative AI in 2026?
Generative AI can create text, code, or images. When combined with multimodality, it becomes even more powerful:
- Cross-modal conversion: Turn text into images or convert videos into detailed summaries.
- Enhanced creativity: Generate richer, context-aware outputs by blending multiple inputs.
- Immersive experiences: Build AI systems that can talk, see, and react, just like humans.
Read More: ChatGPT vs. DeepSeek vs. Google Gemini: Which AI Model is Best for Developers in 2026?
Key Benefits of Multimodal AI for Businesses in 2026
1. Better Contextual Understanding: Like humans, AI combines multiple senses to “get” the full picture.
Example: A chatbot can detect customer frustration by analyzing both voice tone and text message.
2. Cross-Domain Learning: Learns from one field and applies it to another.
Example: Medical AI trained on X-rays and clinical notes adapts to new hospitals.
3. Smarter Virtual Assistants: Support text, speech, images, and video for more natural interactions.
Example: Ask your assistant, “What’s in this photo?”, and it understands both your voice and the image.
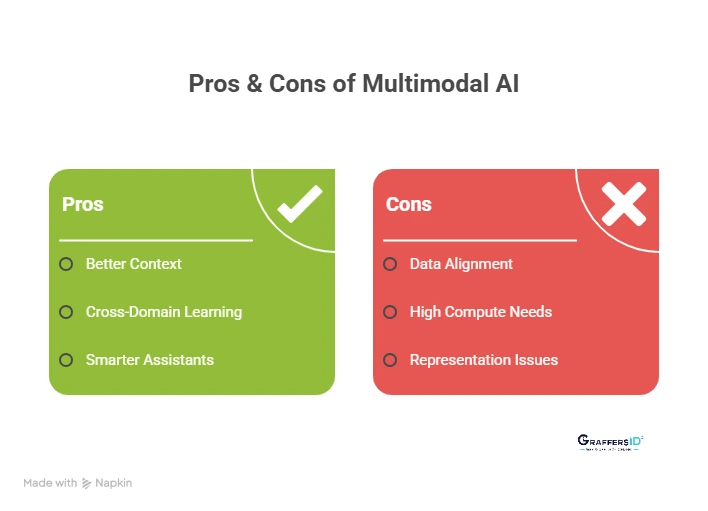
Key Challenges of Multimodal AI in 2026
- Data Alignment: Syncing text, audio, and video is complex (e.g., matching speech to video frames).
- High Compute Needs: Requires large GPUs/TPUs and lots of training data.
- Representation Issues: Converting different data types into comparable forms is tricky.
Despite these challenges, advances in models and cheaper training costs are making multimodal AI more accessible.
Read More: How to Build a Successful AI Adoption Strategy in 2026: A Proven Framework for CEOs and CTOs
Best Multimodal AI Models and Tools to Use in 2026
- GPT-4o (Omni): Real-time text, image, and audio processing with near-human speed.
- Gemini (by Google): Ultra-large context window (up to 2M tokens), great for enterprises.
- CLIP: Links text and images for zero-shot learning.
- DALL-E 3: Accurate, high-quality image generation from text prompts.
- ImageBind (Meta): Integrates six modalities (text, audio, video, depth, thermal, and motion).
- LLaVA: Open-source assistant combining vision and language.
Top Multimodal AI Use Cases and Applications in 2026
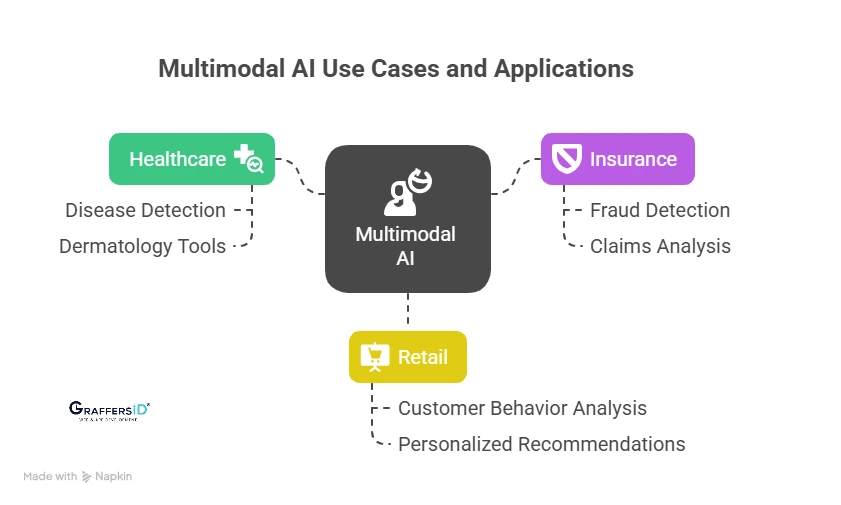
1. Healthcare
- Detects diseases with higher accuracy by combining medical images, patient history, and lab results.
- AI-powered dermatology tools now achieve 90%+ accuracy in skin cancer detection.
2. Insurance
- Analyzes claims using text, images, and videos to spot fraud.
- Reduces 40-60% of false claims while speeding up approvals.
3. Retail
- Uses computer vision and behavior tracking to analyze in-store customer actions.
- Personalizes product recommendations in real time, boosting conversions by 25-35%.

Conclusion
Multimodal AI is not just the future; it’s already here in 2026, transforming industries from healthcare and retail to insurance and education. Its ability to combine text, images, video, and audio makes interactions with machines more human-like, accurate, and contextual than ever before.
Organizations that embrace multimodal AI now will gain a competitive advantage in efficiency, personalization, and innovation. If your business is exploring how to integrate multimodal AI into products or workflows, now is the perfect time to act.
At GraffersID, we help startups and enterprises build AI-powered applications, custom software, and scalable digital solutions with the right tech expertise.
Ready to unlock the power of AI for your business? Connect with GraffersID today!



