
In 2026, voice has become the most natural interface between humans and technology. From AI-powered chatbots that respond instantly to multilingual virtual assistants breaking language barriers, Text-to-Speech (TTS) is no longer a futuristic concept; it’s a core driver of digital transformation.
Unlike the robotic narrations of the past, today’s neural TTS models generate human-like, expressive, and real-time speech that is almost indistinguishable from natural conversation. This leap is powered by deep learning, generative AI, and real-time inference on cloud and edge devices.
This blog breaks down what Text-to-Speech is, how it works, the latest AI advancements, and the key benefits and use cases driving adoption in 2026, helping you decide why your organization should embrace TTS now.
What is Text-to-Speech (TTS)?
Text-to-Speech (TTS) is an AI-powered technology that converts written text into a natural-sounding spoken voice. It allows apps, websites, and devices to “talk” using synthetic voices designed to sound human-like.
-
Traditional TTS (before 2015): Produced robotic, monotone voices with limited language and accent options.
-
Modern TTS (2026): Uses deep learning, neural networks, and generative AI to deliver realistic, expressive, multilingual, and customizable voices that closely mimic human speech patterns.
Quick definition: TTS is artificial intelligence software that transforms digital text into lifelike speech, enabling voice-first user experiences across apps, devices, and enterprise platforms.
How Does Text-to-Speech Work in 2026?
Modern Text-to-Speech (TTS) systems use AI-powered pipelines that transform written text into a natural, human-like voice. In 2026, this process is faster, more expressive, and multilingual thanks to neural networks and generative AI models.
Here’s a step-by-step breakdown of how TTS works:
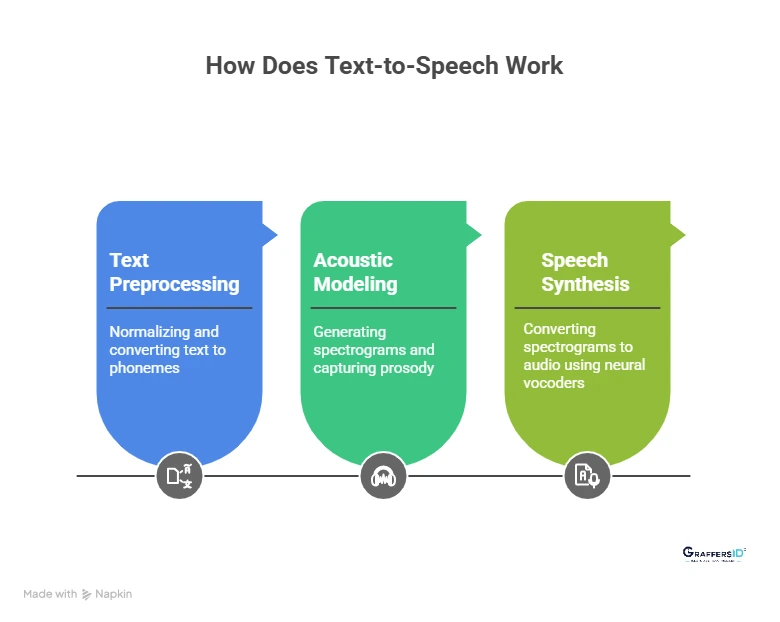
1. Text Preprocessing
-
Normalizes input text by expanding numbers, symbols, and abbreviations.
-
Converts words into phonemes (basic units of speech).
-
Prepares the input for accurate pronunciation and intonation.
2. Acoustic Modeling
-
Uses deep learning algorithms to generate spectrograms (visual representations of sound).
-
Captures prosody, pitch, stress, and rhythm for natural flow.
-
Adds expressive elements like pauses, tone, and emotion.
3. Speech Synthesis with Neural Vocoders
-
Converts spectrograms into audio using neural vocoders such as WaveNet, WaveGlow, or HiFi-GAN.
-
Produces high-quality, real-time speech output that sounds close to human conversation.
Types of Text-to-Speech (TTS) Systems in 2026
Text-to-Speech technology has advanced through multiple generations. In 2026, the four main types of Text-to-Speech systems are Concatenative TTS, Parametric TTS, Neural TTS, and Custom Voice Cloning. Let’s explore each type in detail.
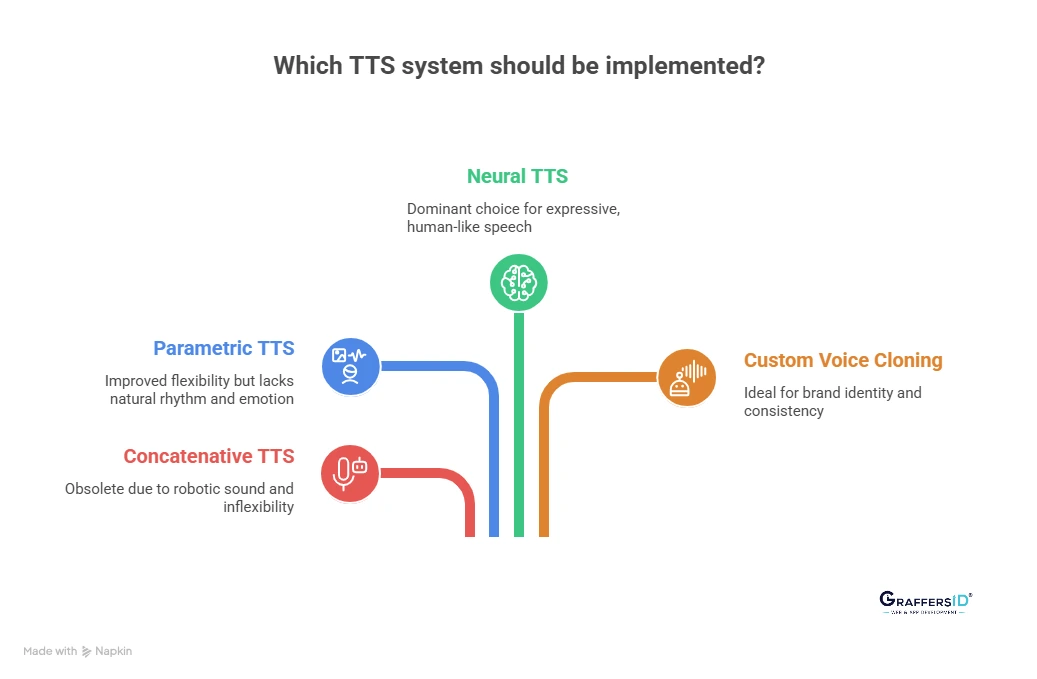
1. Concatenative TTS (Legacy Model)
Early TTS systems pieced together pre-recorded voice segments to form words and sentences. While once common, this approach is now obsolete in 2026 due to its robotic sound and lack of flexibility.
2. Parametric TTS (Statistical Model)
Uses mathematical models to generate speech sounds. Parametric TTS improved flexibility compared to concatenative methods but still lacked natural rhythm, prosody, and human-like emotion.
3. Neural TTS (Modern Standard)
Powered by deep learning and neural networks, this is the dominant TTS system in 2026. Neural TTS produces expressive, human-like, and real-time speech, making it the go-to choice for enterprises, chatbots, and accessibility solutions.
4. Custom Voice Cloning (Brand Identity TTS)
Advanced AI models can now train on a specific speaker’s voice to create a custom synthetic voice. In 2026, companies use voice cloning to build branded voice assistants and maintain consistent brand identity across digital platforms.
Read More: How to Build an AI Voice Agent in 2026: Step-by-Step Guide, Tools, and Future Trends
Key Features of Modern Text-to-Speech (TTS) Technology in 2026
Modern TTS solutions in 2026 go far beyond robotic voices, offering enterprises AI-driven, human-like, and fully customizable speech. Key features include:
-
Human-Like Natural Speech: Neural TTS models now produce voices that closely mimic real human speech patterns, with natural cadence, tone, and pronunciation.
-
Real-Time Streaming & Instant Responses: AI-powered TTS delivers low-latency speech output, enabling instant interactions in chatbots, virtual assistants, and voice-enabled apps.
-
Emotion & Style Control: Enterprises can generate speech with customizable emotion and tone, from formal business narration to casual or empathetic conversation.
-
Multilingual & Multi-Accent Support: Modern TTS systems support multiple languages and regional accents, allowing businesses to scale globally and localize experiences effectively.
-
Low-Latency Cloud and Edge Deployment: Advanced TTS frameworks run efficiently on cloud servers and edge devices, ensuring fast, reliable, and real-time voice generation for critical applications.
-
Customizable & Brand-Specific Voices: Companies can create unique voice identities, reflecting their brand in voice assistants, marketing content, and customer communications.
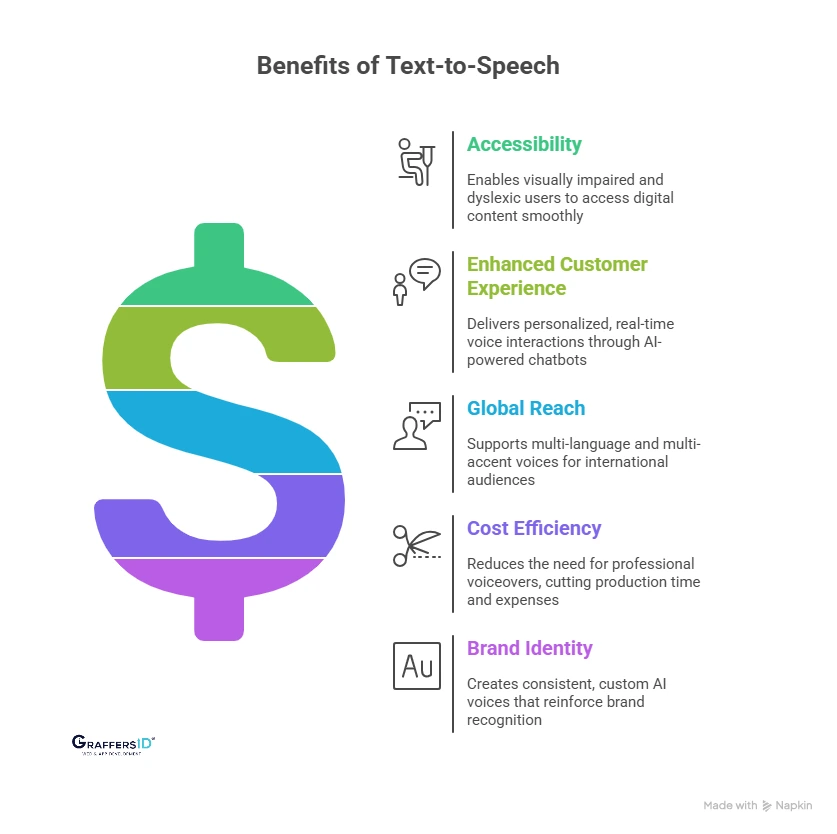
Key Benefits of Text-to-Speech in 2026
-
Accessibility: Enables visually impaired and dyslexic users to access digital content smoothly with natural, human-like voices.
-
Enhanced Customer Experience: Delivers personalized, real-time voice interactions through AI-powered chatbots and virtual assistants.
-
Global Reach: Supports multi-language and multi-accent voices, allowing instant localization of apps and content for international audiences.
-
Cost Efficiency: Reduces the need for professional voiceovers, cutting production time and operational expenses.
-
Brand Identity: Creates consistent, custom AI voices that reinforce brand recognition and enhance engagement across channels.
Enterprise Use Cases of Text-to-Speech in 2026
-
Customer Support & AI Chatbots: Deliver 24/7 multilingual voice assistance for smooth customer interactions and faster query resolution.
-
Education & E-Learning: Power audiobooks, interactive lessons, and language learning apps with natural, engaging voice narration.
-
Healthcare: Enable voice-guided patient support, reminders, and medical instructions for enhanced accessibility.
-
Media & Entertainment: Generate dynamic audiobooks, podcasts, and game character voices with expressive neural TTS.
Read More: AI Voice Generators in 2026: How Enterprises Are Using Text-to-Speech to Scale Communication
Challenges and Ethical Considerations of Text-to-Speech in 2026

-
Voice Deepfakes & Misuse: Advanced TTS can be exploited to create fake voices, increasing risks of fraud and impersonation.
-
Bias in Synthetic Voices: Limited accent, language, and demographic representation can reduce inclusivity and user trust.
-
Data Privacy Risks: Sensitive content in finance, healthcare, or enterprise applications requires secure TTS deployment.
-
High Computational Demands: Real-time, large-scale TTS solutions can incur significant processing and energy costs.
To mitigate these risks, enterprises must follow responsible AI practices and ethical voice guidelines when integrating TTS.
Future of Text-to-Speech: Key Trends for 2026 & Beyond
-
Generative AI + TTS: AI-driven TTS delivers real-time, natural, and expressive voices, enabling zero-shot voice synthesis for instant voice creation.
-
Hyper-Personalized Voices: Advanced TTS adapts tone, style, and accent to individual user preferences, enhancing engagement and user experience.
-
Edge-Based TTS Deployment: Next-gen TTS runs directly on mobile and IoT devices, providing ultra-low latency without cloud dependency.
-
Multimodal AI Integration: TTS is increasingly integrated with avatars, AR/VR, and AI agents, powering immersive and interactive experiences.
-
Voice Rights & Deepfake Regulations: Emerging policies ensure voice ownership protection and prevent misuse of synthetic voices in media and business.

Conclusion: Why AI-Powered Text-to-Speech is Essential for Enterprises in 2026
Text-to-Speech (TTS) has evolved from a niche accessibility tool into a strategic business technology that shapes how companies interact with customers, deliver content, and scale operations globally.
Enterprises adopting AI-driven TTS in 2026 gain clear advantages. As the voice interface becomes the new standard for digital interaction, integrating TTS is no longer optional.
At GraffersID, we specialize in AI-powered solutions, custom TTS integrations, and building voice-first applications for enterprises looking to future-proof their operations.
Ready to leverage AI-driven Text-to-Speech in your business?
Hire expert AI developers or build custom TTS solutions with GraffersID today!



