
Quick Takeaways
- There are 7+ distinct AI model types in active enterprise use in 2026, each suited to fundamentally different problems
- Generative and discriminative models aren’t competing approaches; the most effective production AI systems combine both
- Large language models (LLMs) are a subset of generative AI, not a synonym; confusing them leads to costly infrastructure decisions
- The average enterprise now runs 4.2 AI models in production (Gartner) picking the wrong type isn’t an academic mistake, it’s a budget one
- Foundation models and agentic AI are where 2026 enterprise investment is concentrating; understanding them is no longer optional for CTOs
The average enterprise now runs 4.2 AI models in production, up from just 1.9 in 2023. That number isn’t a flex. For most engineering teams, it’s a sprawl problem.
Here’s what’s actually happening: companies are layering AI into their stacks without a clear mental model of what each system actually does. A generative model gets called an “LLM.” An LLM gets called “AI.” Discriminative classifiers, workhorses running fraud detection and churn prediction for years, suddenly get lumped in with ChatGPT as if they’re the same category of thing. They’re not.
And provisioned, don’t understand what you’re building on, you make bad calls. You provisioned the wrong infrastructure. Hire for the wrong skills. You pay GPT-4 pricing for a task that a fine-tuned classifier could handle for a fraction of the cost.
This guide lays out the 7 core types of AI models active in enterprise environments today, what each one does, how it works at a conceptual level, and when it’s the right tool. If you’re making decisions about AI strategy, architecture, or hiring in 2026, this is the map you need.
Why the AI Model Taxonomy Actually Matters for Your Business
Taxonomy sounds like an academic exercise. It isn’t.
The Cost of Picking the Wrong Model Type
Picture a VP of Product at a Series B SaaS company, 40 engineers, two quarters to ship a personalization engine. The team defaults to an LLM because it’s what everyone’s talking about. Six months later, they’ve got a system that’s expensive to run, slow at inference, and overkill for what’s essentially a recommendation task. A well-tuned discriminative model, or even a collaborative filtering approach, would have done the job better, faster, and at 10% of the compute cost.
This isn’t hypothetical. It’s a pattern at GraffersID we see repeatedly when companies come to us after an AI rebuild. The decision to “just use an LLM” is often the most expensive non-decision a technical team makes.
The global enterprise AI market sat at $114.87 billion in 2026, with machine learning and foundation models accounting for nearly 50% of enterprise adoption. That spending is real. What varies wildly is how much value companies extract from it.
Read Also: Top AI Development Companies in India in 2026: Cost, Services & Expertise
How the 2026 AI Landscape Has Shaken Up Traditional Categories
Three years ago, the model landscape was relatively tidy. You had classical ML for structured data, deep learning for images and NLP, and a nascent wave of large generative models. Now those boundaries are genuinely blurry.
Foundation models now underpin everything from code generation to drug discovery. Agentic AI has moved from research demo to production tool. Gartner projects that 40% of enterprise applications will embed task-specific AI agents by the end of 2026. And multimodal systems have collapsed what used to be separate categories (vision, language, audio) into single architectures.
McKinsey data from 2026 shows 78% of organizations use AI in at least one function. The problem isn’t access anymore. It’s clarity about what you’re actually deploying.
The 7 Core Types of AI Models
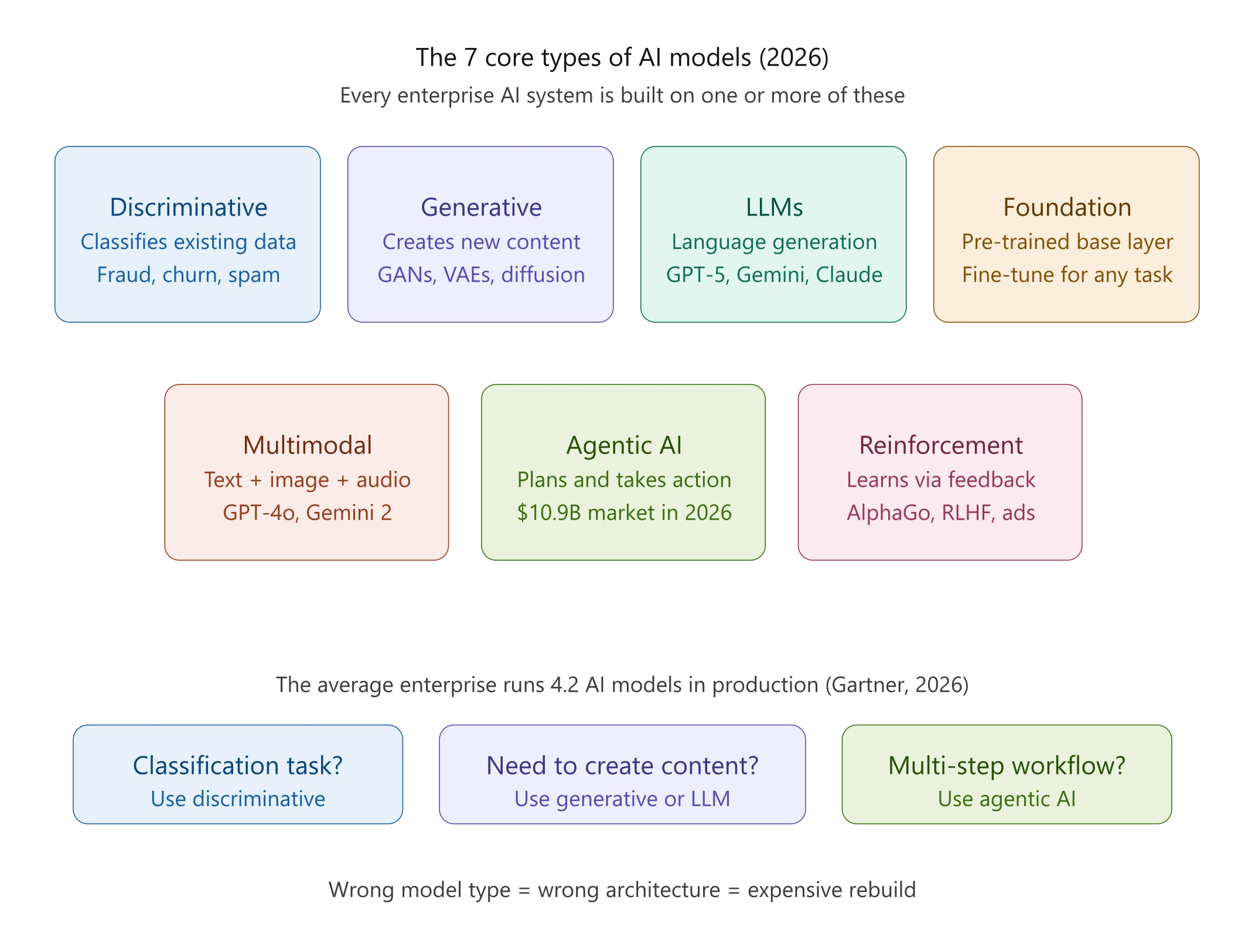
1. Discriminative Models
Discriminative models learn to draw a boundary between categories. Given an input, they output a label or probability: spam or not spam, fraud or legitimate, churn risk or retained. They don’t generate anything. They classify.
These models are trained on labeled data and optimize directly for decision accuracy. Logistic regression, random forests, support vector machines, gradient boosting (think XGBoost) are all discriminative. So are convolutional neural networks (CNNs) when used for image classification.
They’re still the right tool for any problem where you need fast, accurate, explainable decisions on structured data. Fraud detection. Credit scoring. Medical diagnosis from lab values. Customer segmentation. The enterprise AI world didn’t abandon these models. It just started building on top of them.
2. Generative Models
Generative models learn the underlying distribution of data, not just where the boundaries are, but what the data actually looks like. That understanding lets them produce new instances: images, text, audio, synthetic datasets.
Two architectures defined the generative revolution before transformers took over. Generative Adversarial Networks (GANs) pit two neural networks against each other. A generator tries to produce realistic outputs, a discriminator tries to spot fakes. The competition drives quality up. GANs dominated image synthesis through the late 2010s and are still used heavily for video generation and synthetic data creation. Variational Autoencoders (VAEs) take a different approach, encoding data into a compressed latent space and then decoding it back. They’re useful for anomaly detection, data compression, and controlled generation.
By 2026, diffusion models (the architecture behind Stable Diffusion, DALL-E, Midjourney, and Sora) will have largely overtaken GANs for image and video generation. They produce higher-quality outputs with more training stability. To stay current on where top generative AI trends are heading in the enterprise, it’s worth understanding the trajectory. Diffusion is where that investment is going.
3. Large Language Models (LLMs)
LLMs are a specific type of generative model, transformer-based neural networks trained on massive text corpora to predict and generate language. GPT-5, Gemini, Claude, LLaMA, and Mistral are all LLMs. They understand context, syntax, and semantics at a level that earlier NLP systems couldn’t approach.
But here’s what most guides skip: LLMs aren’t magic general-purpose intelligence. They’re statistical pattern machines trained on text. They hallucinate. They’re expensive to serve at scale. And for many tasks, classification, structured prediction, and retrieval, they’re the wrong tool entirely.
For a complete breakdown of what large language models actually are and how to choose one for your specific use case, the key variables are task complexity, latency requirements, and compliance posture. And if you’re evaluating whether a full LLM is even necessary, the SLM vs. LLM decision framework is worth reading. Smaller models outperform in more scenarios than most teams assume.
4. Foundation Models
Foundation models are large pre-trained models built on diverse, massive datasets including text, images, code, audio, and video. They can be fine-tuned or prompted for a wide range of downstream tasks without retraining from scratch. GPT-5, Gemini 2.0, and Claude Opus are foundation models. So is BERT, though it’s architecturally older.
The key distinction: foundation models are the platform; LLMs are one type of foundation model. A foundation model might be multimodal (understanding text and images simultaneously), while an LLM is strictly language-focused.
For CTOs, the strategic question isn’t “should we use a foundation model?” It’s “should we build on a closed API, fine-tune an open-weight model, or train something domain-specific?” Each path has different cost, control, and compliance implications. For a deeper look at foundation models and their enterprise applications, the build-vs-buy calculus is the right place to start.
Read Also: What is AnythingLLM? A 2026 Guide for CTOs to Build Secure Custom AI Agents
5. Multimodal Models
Multimodal models process and reason across multiple data types simultaneously, such as text, images, audio, video, code, and structured data. GPT-4o, Gemini 1.5, and Claude Opus 4.6 all fall here. So does Sora for video generation.
The practical implication: you can feed a multimodal model a screenshot, a PDF, an audio file, and a natural language question and get a unified, contextually grounded response. This collapses workflows that previously required separate specialized models (one for OCR, one for NLP, one for classification) into a single system.
For product teams, multimodal capability is transforming document processing, customer support, medical imaging workflows, and code review. The limitation is cost. Multimodal inference is computationally heavier than pure-text LLM calls. Understanding that trade-off is the difference between a thoughtful architecture and a bill that surprises everyone.
6. Agentic AI Models
Agentic AI is what happens when you give a language model the ability to take actions: browse the web, write and execute code, call APIs, manage files, and coordinate other agents. The model isn’t just generating text in response to a prompt. It’s planning, executing, and iterating toward a goal.
This is the fastest-moving category in enterprise AI right now. The AI agents market hit $10.91 billion in 2026, nearly doubling from 2024. And 51% of enterprises already have AI agents running in production environments. The AI tools reshaping how engineering teams work increasingly sit in this category.
The practical implication for CTOs: agentic systems require a fundamentally different architecture than prompt-response LLM setups. You need tool definitions, memory systems, error handling, and, critically, guardrails. The governance gap here is real. Only 21% of companies have a mature governance model for autonomous agents. That’s the risk most teams are underestimating.
7. Reinforcement Learning Models
Reinforcement learning (RL) models learn through feedback loops. They take actions in an environment, receive reward signals, and adjust behavior to maximize long-term outcomes. No labeled dataset. No static training distribution. The model learns by doing.
RL is behind AlphaGo, autonomous robotics, real-time bidding systems, and, less visibly, the fine-tuning process that aligns modern LLMs to human preferences (RLHF: Reinforcement Learning from Human Feedback). It’s also the architecture powering recommendation engines at platforms like YouTube and Netflix, where the “environment” is user behavior and the “reward” is engagement.
For most product teams, RL isn’t something you build from scratch. It’s something you need your AI developers to understand deeply, because it’s embedded in the systems you’re building on.
Generative vs. Discriminative AI: What’s the Real Difference?
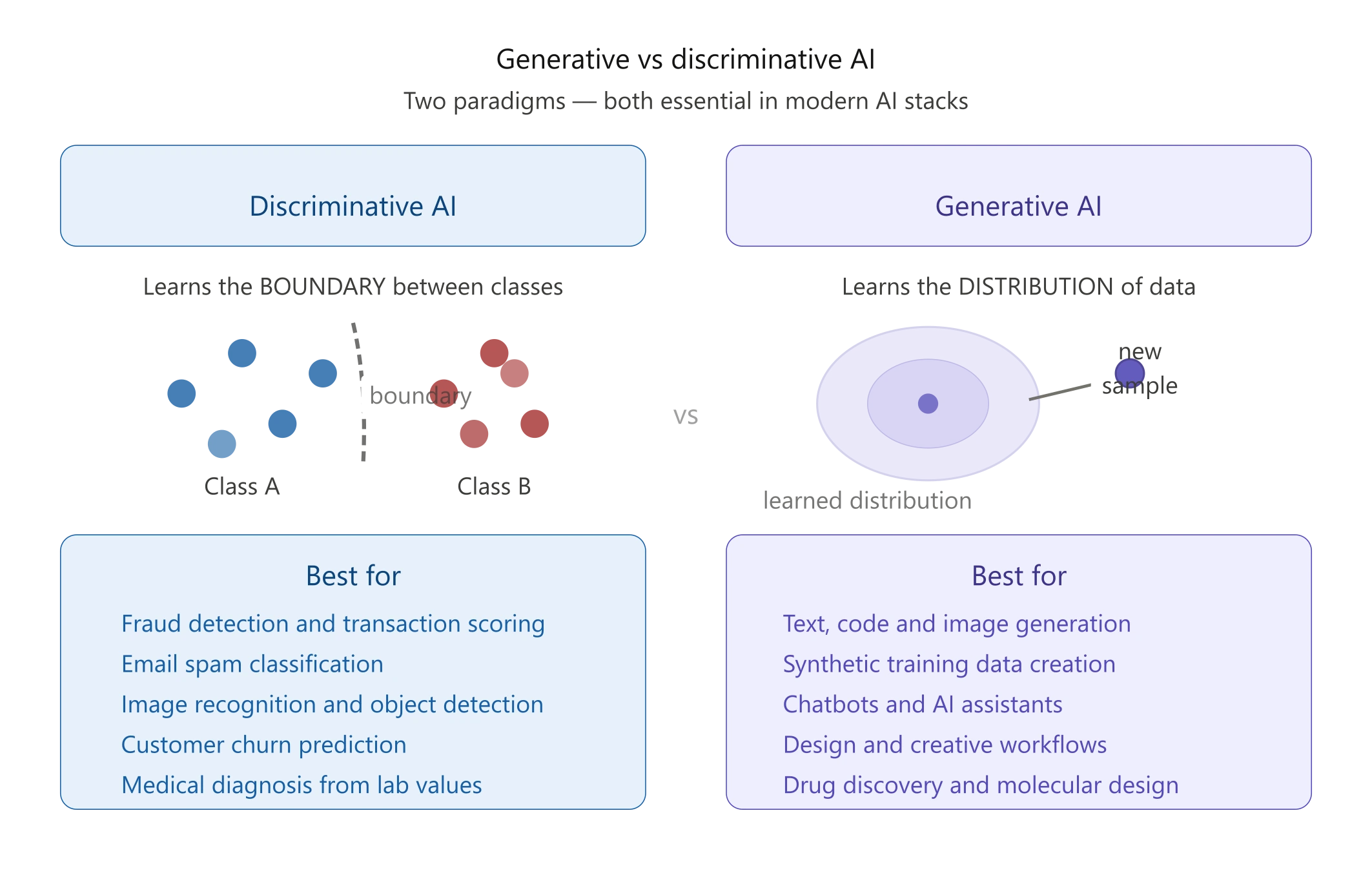
The clearest way to think about this: discriminative models answer the question “which bucket does this belong in?” Generative models answer “what would a new example from this distribution look like?”
Discriminative models learn the boundary between classes. Given a transaction, is it fraud or not? They’re fast, accurate on labeled data, and highly interpretable, which matters in regulated industries. The limitation is that they can’t create. They can only classify.
Generative models learn the entire data distribution, not just the boundary. That’s why they can produce new text, images, or synthetic data that resembles what they were trained on. But that additional capability comes with complexity: more parameters, more training data, more compute, and a higher risk of plausible-sounding errors.
Which One Should Your Team Actually Build On?
Here’s the honest answer: both, probably. The most effective production AI systems in 2026 combine both approaches. Generative models create content or synthetic training data; discriminative models filter, validate, and classify the output. A customer support system might use a generative LLM to draft responses and a discriminative classifier to flag responses that fall outside acceptable confidence bounds before they reach a customer.
The decision isn’t binary. It’s architectural.
What Are Foundation Models, and Why Do CTOs Keep Talking About Them?
Foundation models matter because they’ve changed the economics of AI development. Before them, every AI application required training a model from scratch on domain-specific data, expensive, time-consuming, and accessible only to organizations with serious ML infrastructure. Foundation models shifted the default: start with a powerful pre-trained base, then fine-tune or prompt-engineer for your specific task.
The strategic implication is significant. A startup with no ML team can now build a production-grade AI feature by calling an API. An enterprise with compliance requirements can fine-tune an open-weight model like LLaMA on proprietary data without sending that data to a third-party API. A product team can prototype in days what would have taken months to train.
For choosing the right LLM for your development team, the foundation model question is always lurking underneath: are you optimizing for capability, cost, data privacy, or customizability? Each foundation model makes different trade-offs on each dimension.
Read Also: What Are LLMs? Benefits, Use Cases and Top Models in 2026
How to Choose the Right AI Model Type for Your Product
Match the Model to the Task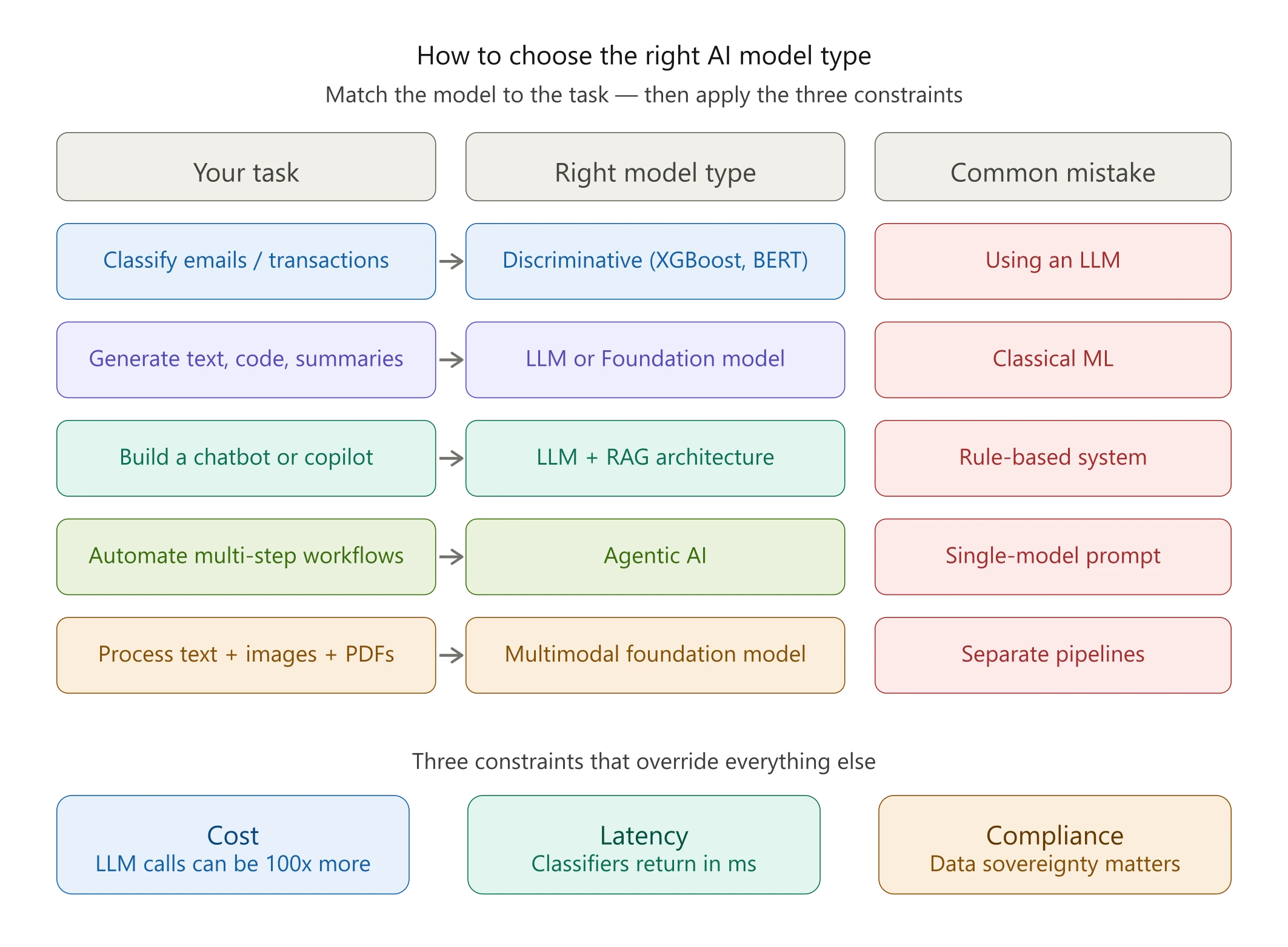
Cost, Latency, and Compliance: The Three Constraints That Should Drive Your Choice
Cost is the most underestimated variable. A discriminative classifier running locally costs fractions of a cent per inference. An LLM API call with a long context window can cost hundreds of times more at scale. Before defaulting to a foundation model, run the numbers at your expected inference volume.
Latency shapes your architecture choices more than capability does in many real-time applications. Generative models are inherently slower. They produce tokens sequentially. Discriminative models return predictions in milliseconds. If you’re building a real-time fraud detection system, that difference isn’t theoretical.
Compliance is where teams most often underestimate risk. Sending sensitive data to a third-party LLM API may violate GDPR, HIPAA, or your customer contracts. Open-weight models deployed on your own infrastructure eliminate that risk but add operational overhead. You can’t outsource the compliance decision to the model vendor. Building with PyTorch for training AI models on your own data is often the path for teams with serious data sovereignty requirements.
The Biggest Misconception About AI Model Types
“LLM” Doesn’t Mean “AI,” and Confusing Them Is Costing Teams Money
Here’s a misconception that’s genuinely expensive in 2026: treating “LLM” and “AI” as interchangeable. You hear it constantly. A job posting asks for “AI experience” and means “can you prompt ChatGPT?” A product roadmap says “we’re going AI-first” and the plan is to add a GPT wrapper.
LLMs are one category of AI model, a powerful, versatile, and genuinely transformative one. But they’re not the totality of AI. The discriminative models running your recommendation engine, the RL systems optimizing your ad spend, the CNN classifying defects in your manufacturing line, those are all AI too. And they’re often doing the quietly critical work that your LLM gets the credit for.
The teams that understand the full taxonomy make better hiring decisions. They build leaner architectures. They spend compute budgets more deliberately. And they don’t end up rebuilding systems six months later because they chose the flashiest tool instead of the right one.
Counterintuitively, the most sophisticated AI teams in 2026 are often the ones using the smallest models for any given task, not the largest.
Conclusion
The 2026 AI landscape isn’t simple, but it’s not as opaque as it looks from the outside. Seven model categories cover the vast majority of what’s in production: discriminative models for classification, generative models and LLMs for creation, foundation models as the new platform layer, multimodal systems for cross-format reasoning, agentic AI for autonomous task execution, and reinforcement learning for dynamic optimization.
The practical takeaway: match the model to the task, constrain your choices by cost, latency, and compliance, and resist the pull toward using the most-discussed model rather than the most appropriate one. That’s what separates teams that build well from teams that rebuild often.
At GraffersID, we’ve helped 200+ startups and enterprises build AI-powered products, and the most common gap we fill isn’t just development capacity. It’s developers who understand which AI model type solves which problem. If that’s the gap on your team right now, we can help.
Ready to build AI features your architecture can actually sustain? At GraffersID, we provide pre-vetted AI developers skilled across the full model landscape, from discriminative classifiers to agentic systems, ready to onboard in 48 hours. Talk to our team , no commitment, just a conversation.


