
The competition to build and deploy large language models (LLMs) has reached an advanced level in 2026. Businesses, developers, and entrepreneurs are now building and customizing AI rather than just consuming it. LLaMA (Large Language Model Meta AI) is a revolutionary series from Meta that offers an open-weight alternative to proprietary models such as Claude 3 and GPT-4.5.
This article delves into LLaMA’s history, technical architecture, main advantages, and how development teams can use it for practical use cases.
What is Meta’s LLaMA AI?
LLaMA (Large Language Model Meta AI) is Meta’s family of foundational AI models designed for natural language processing (NLP) and generative tasks. It was created to democratize access to powerful LLMs by offering open weights, allowing developers to inspect, modify, and deploy the models freely.
Evolution Overview:
- LLaMA 1 (Feb 2023): Research-focused release with high performance at 7B–65B parameter sizes. Non-commercial use.
- LLaMA 2 (July 2023): Open weights with commercial licensing, improved instruction tuning.
- LLaMA 3 (April 2024): Longer context windows, improved linguistic support, and cutting-edge performance on MMLU, ARC, and BIG-bench Hard are the main features of the current generation model.
Key Features of Meta LLaMA 3 in 2026
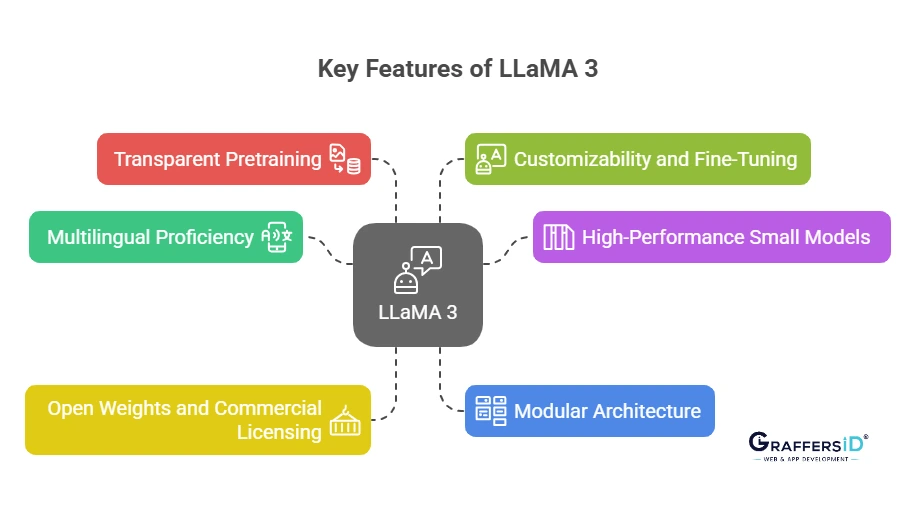
1. Multilingual Proficiency
Offers competitive accuracy in more than 30 languages. In non-English languages such as German, Hindi, Mandarin, and Spanish, LLaMA 3 performs better than previous versions in reasoning, translation, and code generation tasks.
2. High-Performance Small Models
Even the 7B and 13B versions outperform older 65B models from 2023. LLaMA 3’s architecture improvements allow better inference quality with smaller compute budgets.
3. Open Weights and Commercial Licensing
Unlike GPT and Claude, the weights of LLaMA 3 can be downloaded and self-hosted under a commercially friendly license. This provides companies with flexibility to adapt, deploy, and enhance without vendor lock-in.
4. Modular Architecture
Designed to be plug-and-play with frameworks like Hugging Face Transformers, LangChain, and LlamaIndex. The model can be sliced, quantized, or converted for ONNX, GGML, or TensorRT deployment.
5. Transparent Pretraining
Meta released partial documentation on its data pipeline, indicating better data hygiene and content filtering. While not 100% transparent, this is a major step up in model explainability.
6. Customizability and Fine-Tuning
LLaMA 3 supports adapters like LoRA, QLoRA, and PEFT-based fine-tuning. Developers can retrain models using as little as 4GB VRAM on domain-specific data.
Read More: What Are LLMs? Benefits, Use Cases, & Top Models in 2026
Technical Benefits of Meta LLaMA for Developers

1. Performance-Per-Compute
LLaMA models offer high token prediction accuracy per FLOP. This allows 13B models to execute with reasonable latency on consumer-grade high-end GPUs like the RTX 3090 or A100.
2. Customizability
Developers can:
- Fine-tune with low-rank adapters (LoRA, QLoRA).
- Inject domain-specific data (e.g., finance, healthcare, law).
- Integrate RAG pipelines with vector databases like FAISS or Pinecone.
3. Interoperability
LLaMA is interoperable with:
- ONNX (Open Neural Network Exchange): Allows LLaMA to run in different situations, such as Windows, mobile devices, or edge devices.
- TensorRT: NVIDIA’s high-performance inference engine for optimized GPU serving.
- vLLM, FlashAttention 2: Used to serve faster and cheaper inference with batch support and long context windows.
4. Cost-Efficiency
There are no per-token or API-based billing models. Once deployed, your only cost is hosting. Compared to GPT-4 API charges (~$0.06–$0.12/1k tokens), this model offers massive savings.
5. Tooling Ecosystem
LLaMA is deeply embedded in the 2026 AI tooling ecosystem:
- LangChain for workflow chaining.
- LlamaIndex for document retrieval.
- FastAPI/Flask for serving locally via REST APIs.
6. Transparency
The ability to view and inspect weights gives full visibility into model biases and reasoning, which is critical for compliance in regulated industries.
Real-World Use Cases of Meta Llama for Developers & Tech Teams
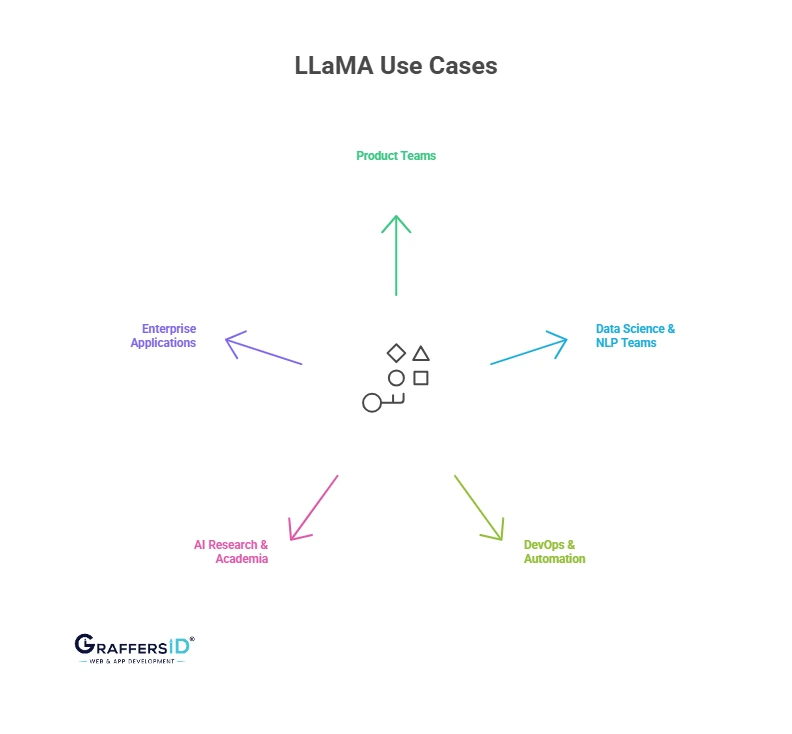
1. Product Teams
- In-app Chat Assistants: Use LLaMA for intelligent in-app chatbots for support, onboarding, or education.
- Context-Aware Recommendations: Customize app recommendations for news, music, and shopping.
- Automatic Summarization: Transform lengthy data, such as emails, logs, or articles, into concise, useful summaries.
2. Data Science & NLP Teams
- Domain-Specific Q&A Bots: Train on internal knowledge bases or research papers.
- Data Annotation Assistants: Recommend and tag entities in text for NLP model training.
- Topic Modeling & Entity Recognition: Enhance data pipelines through LLaMA-enhanced understanding.
3. DevOps & Automation
- Smart Scripting: Use LLaMA to create Bash, Docker, YAML, or CI/CD scripts.
- Log Analysis Bots: Analyze logs and flag anomalies or security issues.
- Infra-as-Code Assistants: Create Kubernetes or Terraform specifications from prompts.
4. AI Research & Academia
- Base for Experiments: Modify the architecture and test new layers or tokenization methods.
- Alignment Studies: Use LLaMA for RLHF or Constitutional AI research.
- Language Evaluation: Use it as a baseline for benchmarking multilingual or domain-specific tasks.
5. Enterprise Applications
- Legal Document Q&A: Create bots that answer questions from contracts or case laws.
- HR Assistants: Summarize job applications or answer company policy queries.
- Financial Forecasting Bots: Assist in interpreting reports or predicting risks using domain-tuned LLaMA.
How to Get Started with Meta LLaMA in 2026?
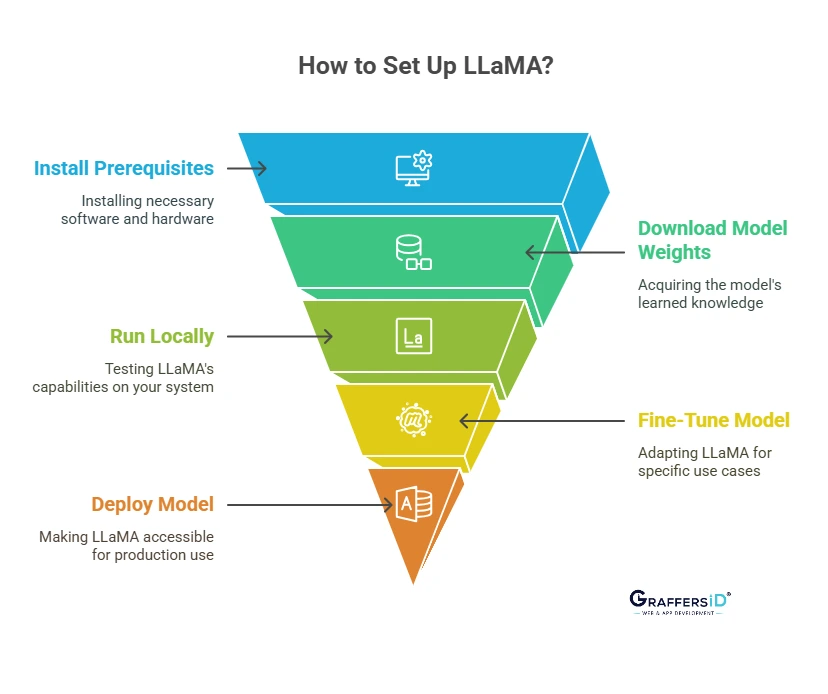
1. Prerequisites
You must first properly set up your environment in order to use LLaMA 3 effectively. You can load, run, and modify the model using these tools and dependencies:
- Python 3.10+: For running modern ML libraries.
- PyTorch 2.1+: Core framework for LLaMA’s architecture.
- Hugging Face Transformers: Handles model loading and tokenization.
- GPU Setup: 24 GB+ VRAM recommended for smooth inference with 13B models. Quantized versions can run on 8GB GPUs.
2. Downloading Model Weights
LLaMA requires actual model weights, or the learned information of the neural network. Meta offers them through reliable platforms:
- Go to HuggingFace Meta-LLaMA Repo.
- Request access (if required) and authenticate.
- Download 7B, 13B, or 34B checkpoints as .bin or safetensors.
Why this step? Without weights, your code won’t have the “brain” of the model—it’s like running software without data.
3. Running Locally
Once you have the model and dependencies set up, you can load and run it locally. This allows you to experiment with LLaMA’s functionality without having to use APIs. It’s good for development, debugging, and testing prompt behavior on your local system. Use the following code:
from transformers import AutoTokenizer, AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained(“meta-llama/Llama-3-13B”)
tokenizer = AutoTokenizer.from_pretrained(“meta-llama/Llama-3-13B”)
input_ids = tokenizer(“Write a Python script to scrape websites.”, return_tensors=”pt”).input_ids
output = model.generate(input_ids, max_new_tokens=100)
print(tokenizer.decode(output[0]))
4. Fine-Tuning and Adaptation
To make LLaMA more useful for your business or use case, you can fine-tune it on your own data. Here are the common, cost-efficient methods:
- LoRA (Low-Rank Adaptation): Trainable adapter layers using 8-bit quantization (saves VRAM).
- QLoRA (Quantized LoRA): Even more efficient for GPUs with <16GB VRAM.
- PEFT (Parameter-Efficient Fine-Tuning): Hugging Face’s library for parameter-efficient training.
5. Deployment Options
Once LLaMA is ready for operational use, it must be served in a way that allows users and apps to communicate with it. These are the most prevalent deployment strategies:
- Self-hosted: Docker + FastAPI + Gunicorn stack for internal API.
- Cloud Providers: RunPod, Paperspace, Lambda Labs, AWS EC2 (A100/GH200).
- Serverless AI: Modal, Replicate, or NVIDIA NIM for scalable endpoint hosting.
Read More: ChatGPT vs. DeepSeek vs. Google Gemini: Which AI Model is Best for Developers?
LLaMA vs Other LLMs in 2026: Full Comparison
Here’s a side-by-side breakdown of how LLaMA 3 stacks up against GPT-4 (OpenAI), Claude 3 (Anthropic), and Perplexity AI:
| Feature | LLaMA 3 | GPT-4.5 | Claude 3 | Perplexity AI |
| Open-Source | Yes (weights available) | No | No | No |
| Cost Involved | Low (self-hosted or cloud GPU) | High (API usage based) | High (API usage based) | Moderate (API + citations) |
| Fine-Tuning | Full (QLoRA, LoRA, PEFT) | Limited (via API only) | Closed-source | Closed-source |
| Multilingual Support | Experimental (in dev) | Yes (Vision, Text, Audio) | Yes (Vision, Text) | Text-only |
| Context Length | 65K+ | 128K | 200K+ | 100K+ |
| Best Use Cases | Custom LLMs, on-premise AI | SaaS apps, enterprise AI | Summarization, reasoning | Search + LLM (RAG) |

Final Thoughts: Should Your Tech Team Use Meta LLaMA in 2026?
In the open-source AI market, Meta’s LLaMA 3 provides incomparable performance, flexibility, and cost control. LLaMA is the ideal option for teams that require scalable, customizable LLMs with no vendor lock-in and API restrictions.
LLaMA 3 gives developers complete control over the model pipeline, allowing them to build custom generative AI solutions from quick prototyping to production-ready deployment.
GraffersID specializes in developing scalable AI systems with modern open-source tools like LLaMA. Our expertise can help you succeed in building intelligent chatbots.
Hire AI developers from India who are skilled in LLM deployment, fine-tuning, and inference optimization. Contact Us Now!



